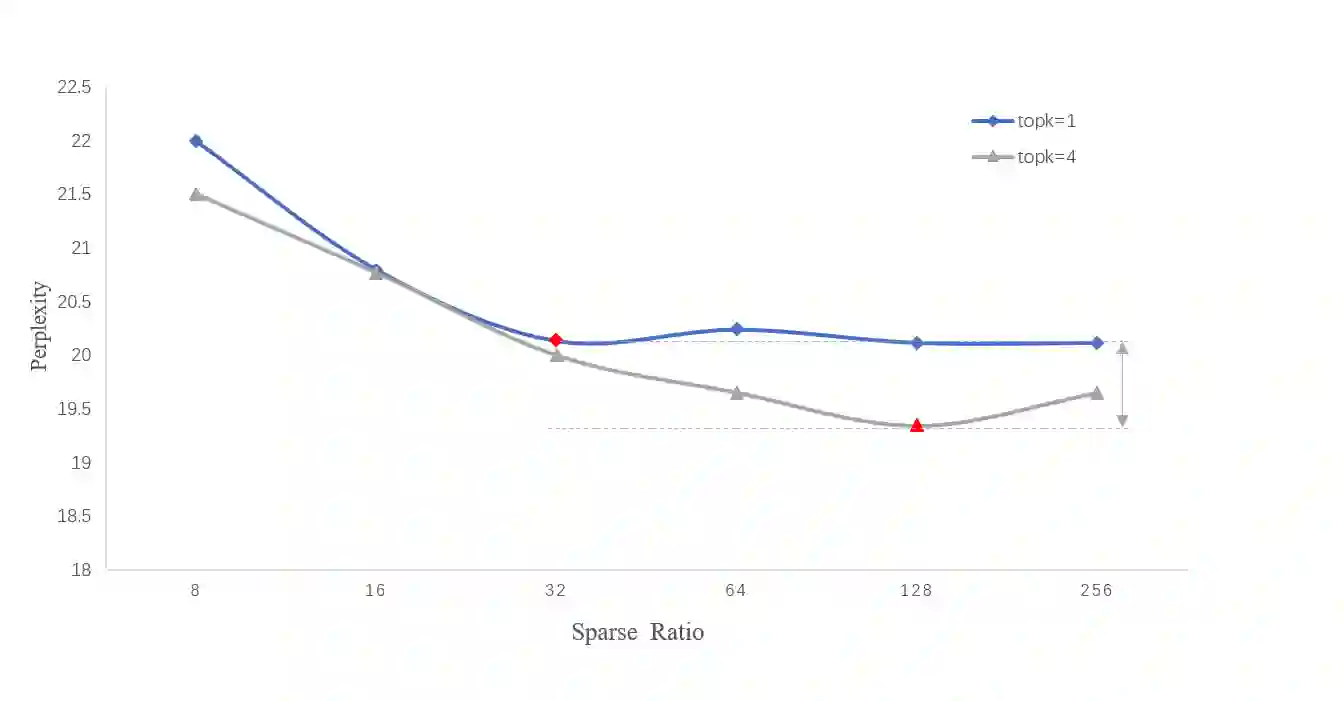
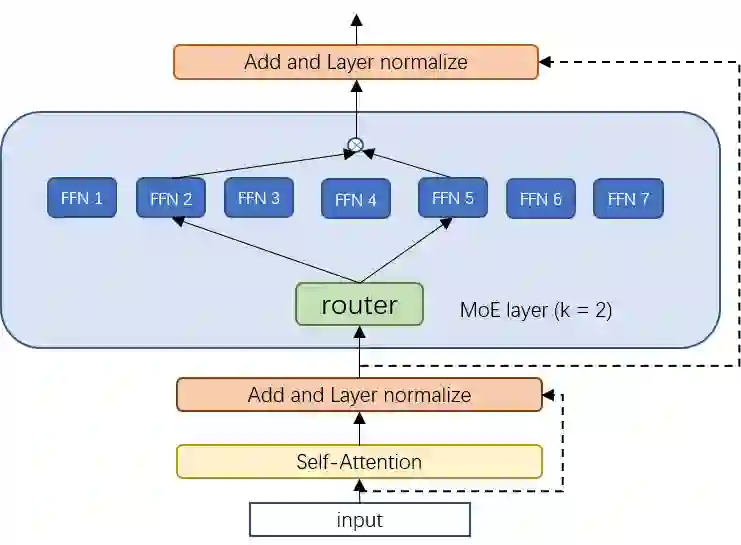
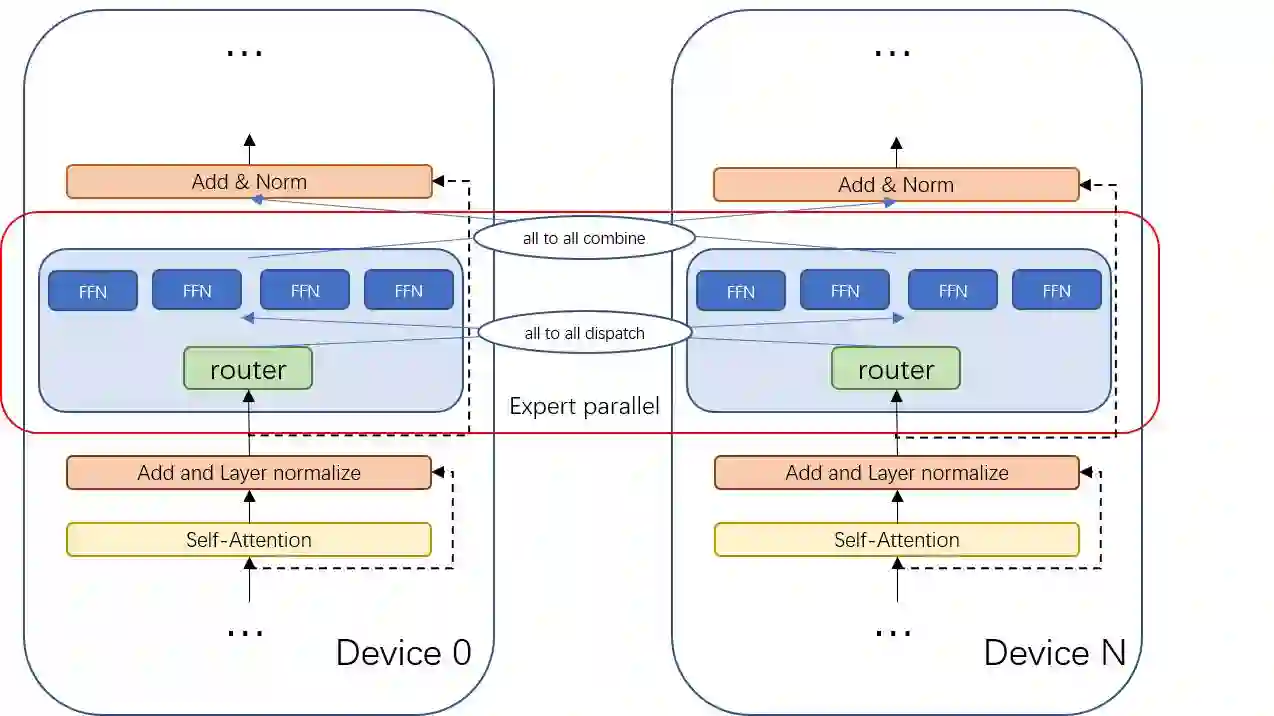
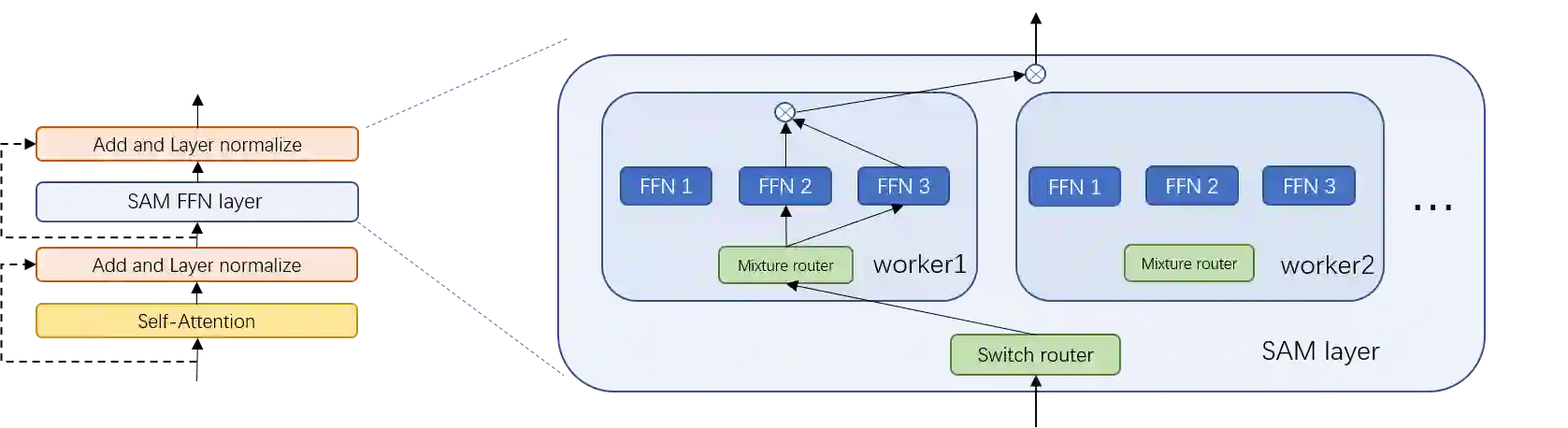
The sparsely-activated models have achieved great success in natural language processing through large-scale parameters and relatively low computational cost, and gradually become a feasible technique for training and implementing extremely large models. Due to the limit of communication cost, activating multiple experts is hardly affordable during training and inference. Therefore, previous work usually activate just one expert at a time to alleviate additional communication cost. Such routing mechanism limits the upper bound of model performance. In this paper, we first investigate a phenomenon that increasing the number of activated experts can boost the model performance with higher sparse ratio. To increase the number of activated experts without an increase in computational cost, we propose SAM (Switch and Mixture) routing, an efficient hierarchical routing mechanism that activates multiple experts in a same device (GPU). Our methods shed light on the training of extremely large sparse models and experiments prove that our models can achieve significant performance gain with great efficiency improvement.
翻译:由于通信成本有限,在培训和推论期间,很难负担得起多专家的启动费用。因此,以往的工作通常每次只激活一名专家,以减轻额外的通信费用。这种路由机制限制了模型性能的上限。在本文件中,我们首先调查了一种现象,即增加活跃专家的人数可以提高模型性能,而少得可怜。为了增加活跃专家的人数,而不增加计算成本,我们提议采用SAM(变换和混合)路由,即高效的分层路由机制,即在同一设备中激活多位专家(GPU),我们的方法展示了对极为稀少模型的培训以及实验,证明我们的模式可以大大提高效率,从而取得显著的业绩收益。