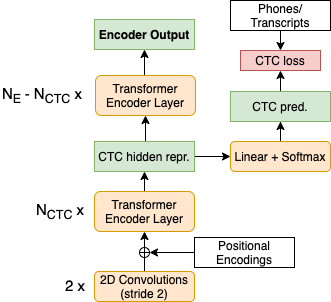
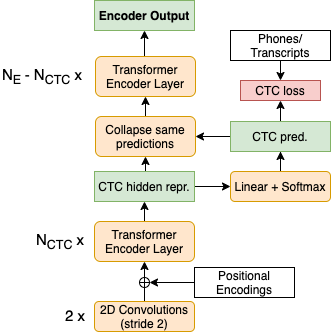
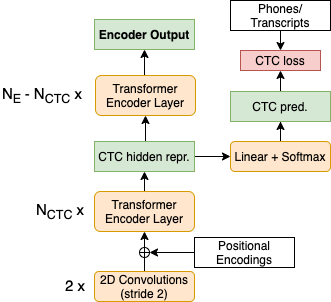
Previous studies demonstrated that a dynamic phone-informed compression of the input audio is beneficial for speech translation (ST). However, they required a dedicated model for phone recognition and did not test this solution for direct ST, in which a single model translates the input audio into the target language without intermediate representations. In this work, we propose the first method able to perform a dynamic compression of the input indirect ST models. In particular, we exploit the Connectionist Temporal Classification (CTC) to compress the input sequence according to its phonetic characteristics. Our experiments demonstrate that our solution brings a 1.3-1.5 BLEU improvement over a strong baseline on two language pairs (English-Italian and English-German), contextually reducing the memory footprint by more than 10%.
翻译:先前的研究显示,对输入音频进行动态的电话知情压缩有利于语音翻译。然而,它们需要专用电话识别模式,而没有测试这种直接识别的解决方案,即一个单一模式将输入音频翻译为目标语言,而没有中间代表。在这项工作中,我们提出第一个能够对输入音频的输入间接压缩的方法。特别是,我们利用连接时空分类(CTC)根据语音特征压缩输入序列。我们的实验表明,我们的解决方案带来了1.3-1.5 BLEU的改进,超越了两种语言(英语-意大利语和英语-德语)的强力基线,在背景上将记忆足迹减少10%以上。