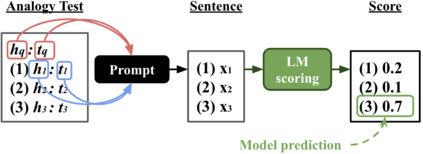
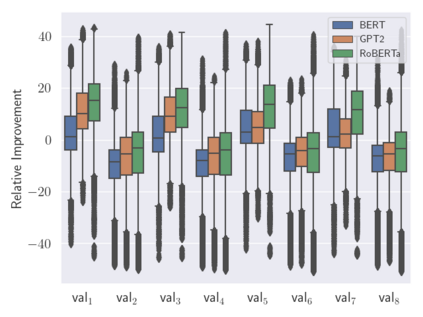
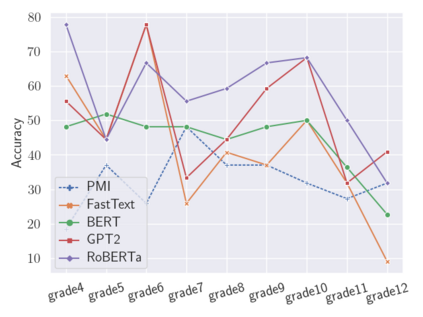
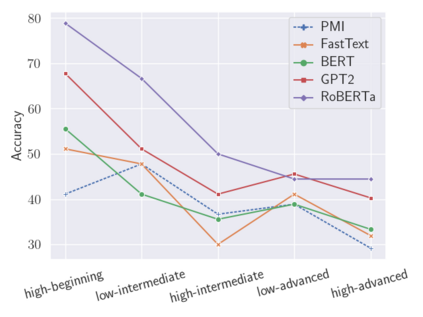
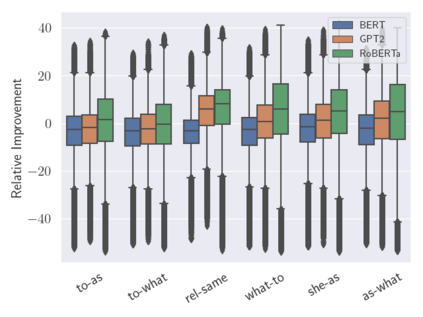
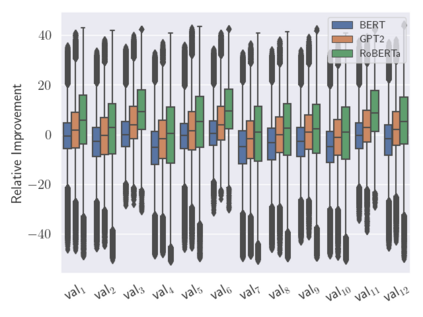
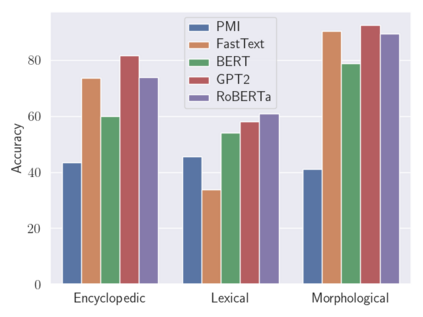
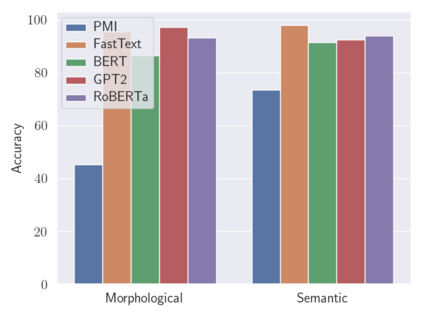
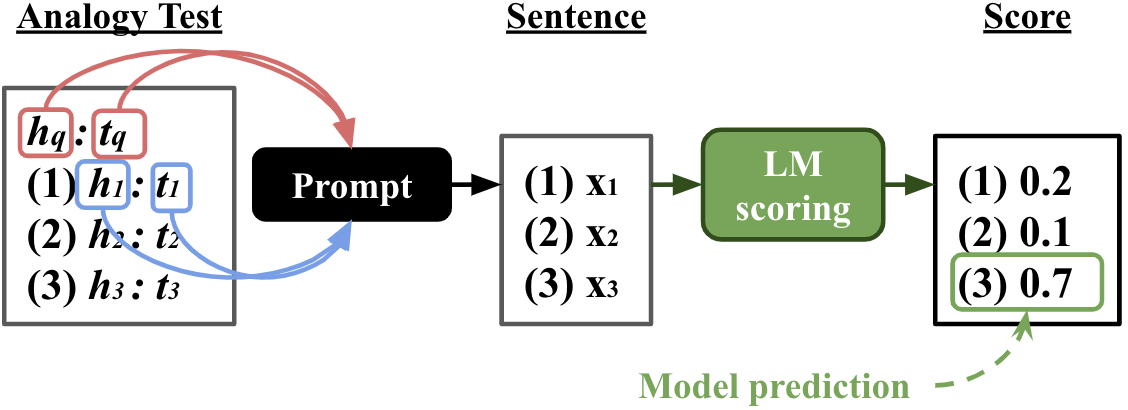
Analogies play a central role in human commonsense reasoning. The ability to recognize analogies such as "eye is to seeing what ear is to hearing", sometimes referred to as analogical proportions, shape how we structure knowledge and understand language. Surprisingly, however, the task of identifying such analogies has not yet received much attention in the language model era. In this paper, we analyze the capabilities of transformer-based language models on this unsupervised task, using benchmarks obtained from educational settings, as well as more commonly used datasets. We find that off-the-shelf language models can identify analogies to a certain extent, but struggle with abstract and complex relations, and results are highly sensitive to model architecture and hyperparameters. Overall the best results were obtained with GPT-2 and RoBERTa, while configurations using BERT were not able to outperform word embedding models. Our results raise important questions for future work about how, and to what extent, pre-trained language models capture knowledge about abstract semantic relations.
翻译:模拟在人类常识推理中发挥着核心作用。 识别“ 眼就是看到耳听” 等类比的能力有时被称为类比比例, 塑造我们如何构建知识和理解语言。 然而,令人惊讶的是, 在语言模型时代, 识别此类类比的任务尚未受到重视。 在本文件中, 我们利用从教育环境获得的基准以及更常用的数据集, 分析基于变压器的语言模型在这项不受监督的任务上的能力。 我们发现, 现成语言模型可以在某种程度上识别类比, 但与抽象和复杂的关系挣扎, 并且结果对于模型架构和超度参数非常敏感。 总体而言, 与 GPT-2 和 RoBERTA 相比, 获得的最佳结果是获得的, 而使用 BERT 的配置无法超越语言嵌入模型。 我们的结果为未来的工作提出了重要问题, 是如何, 以及如何, 以及在多大程度上, 事先培训的语言模型获取抽象的语义关系知识。