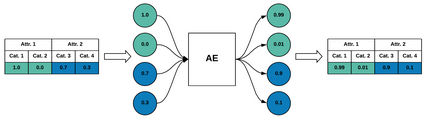
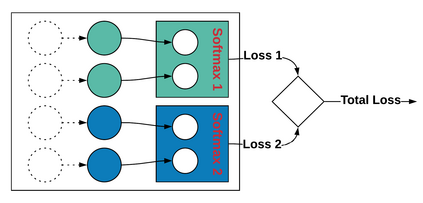
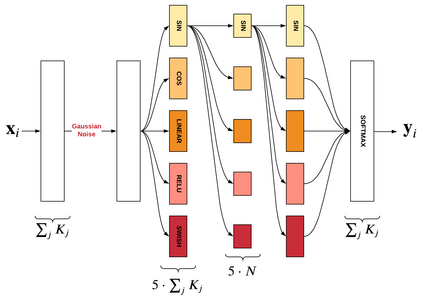
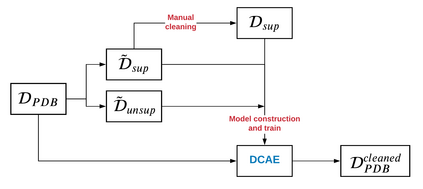
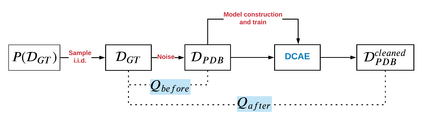
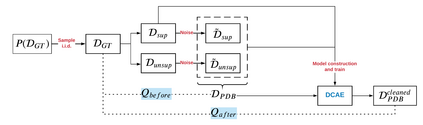
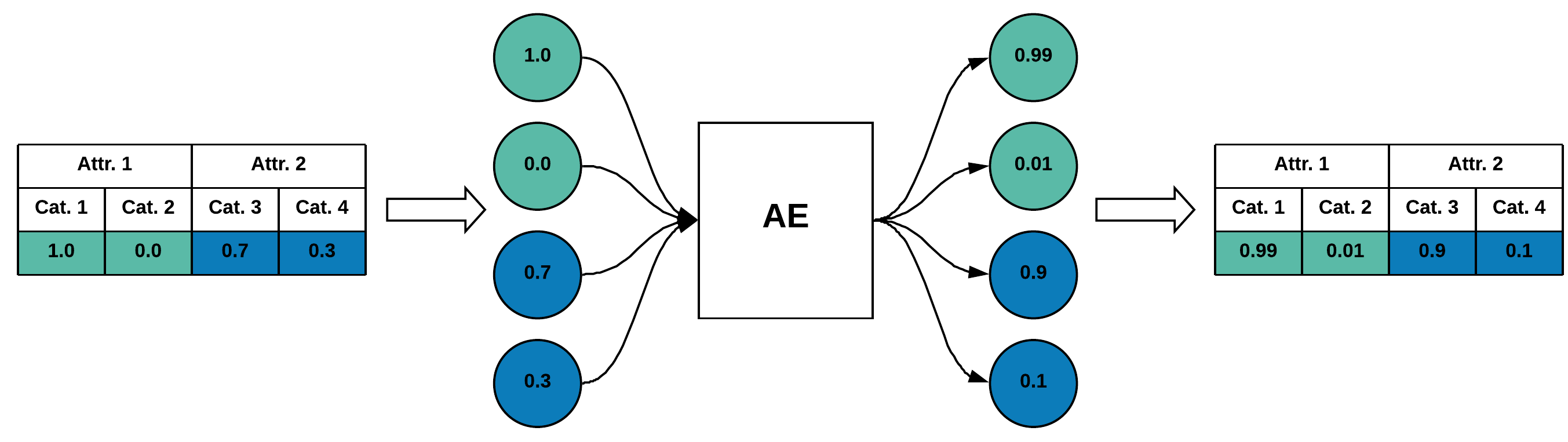
Data quality problems are a large threat in data science. In this paper, we propose a data-cleaning autoencoder capable of near-automatic data quality improvement. It learns the structure and dependencies in the data and uses it as evidence to identify and correct doubtful values. We apply a probabilistic database approach to represent weak and strong evidence for attribute value repairs. A theoretical framework is provided, and experiments show that it can remove significant amounts of noise (i.e., data quality problems) from categorical and numeric probabilistic data. Our method does not require clean data. We do, however, show that manually cleaning a small fraction of the data significantly improves performance.
翻译:数据质量问题是数据科学的一大威胁。在本文中,我们建议建立一个能够近自动数据质量改进的数据清理自动编码器。它学习数据的结构和依赖性,并将其作为证据来识别和纠正可疑值。我们采用概率数据库方法来代表薄弱和有力的属性价值修复证据。我们提供了理论框架,实验表明它能够从绝对和数字概率数据中去除大量噪音(即数据质量问题)。我们的方法不需要清洁数据。但我们确实表明,人工清理数据中的一小部分能显著改善性能。