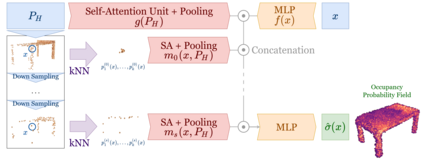
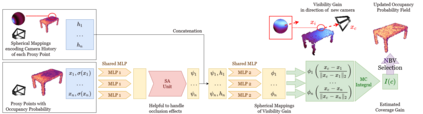
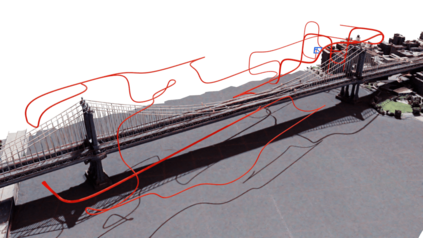
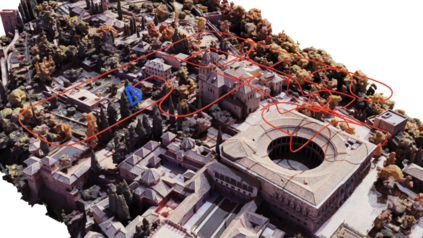
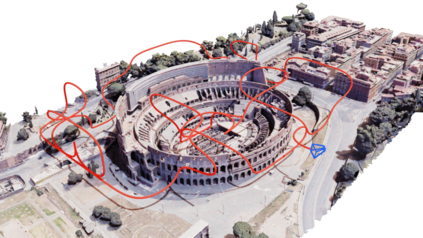
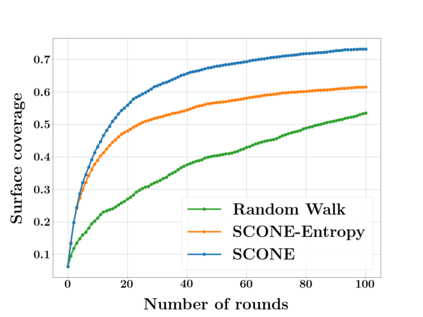
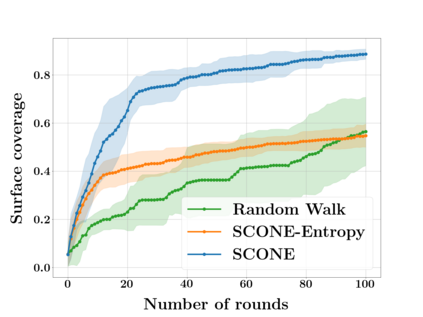
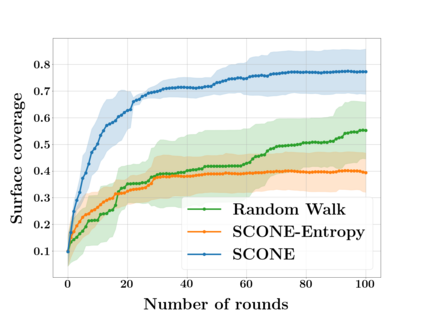
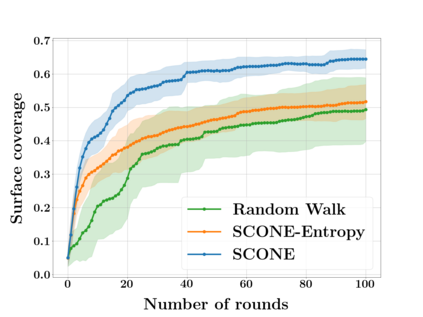
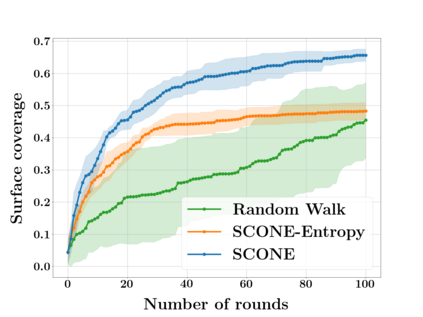
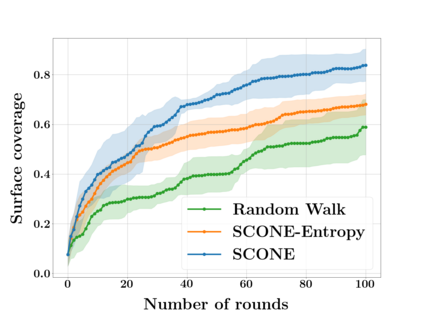
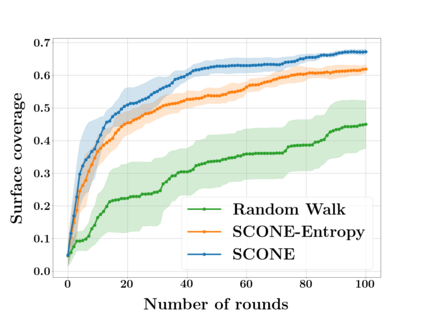
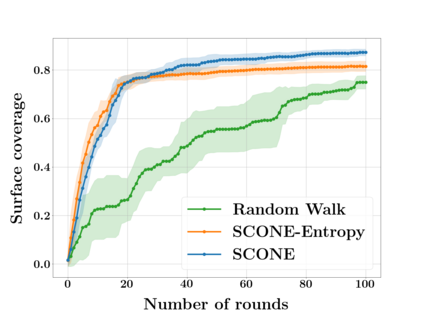
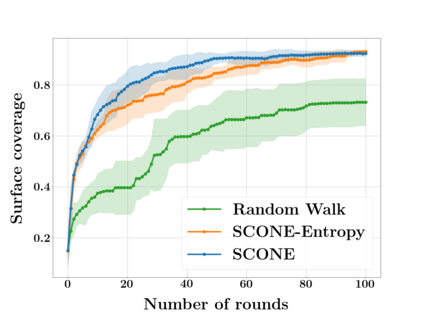
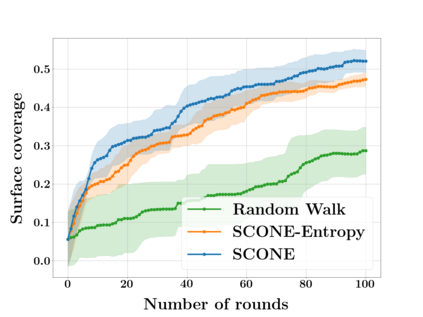
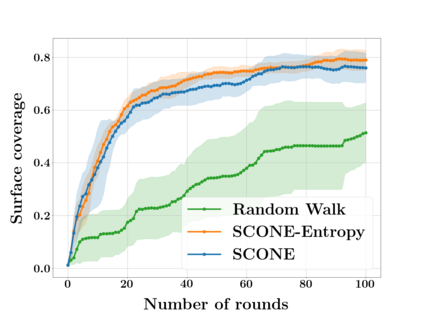
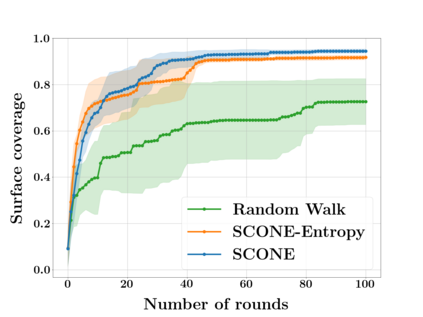
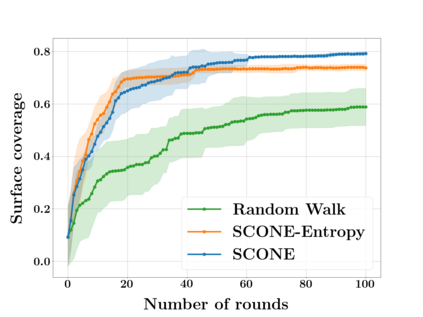
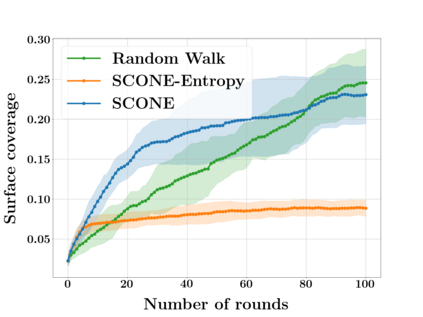
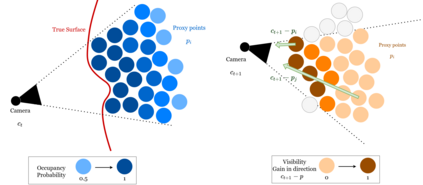
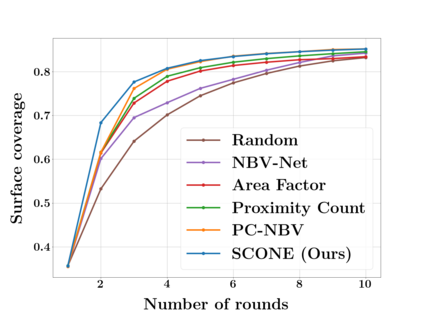
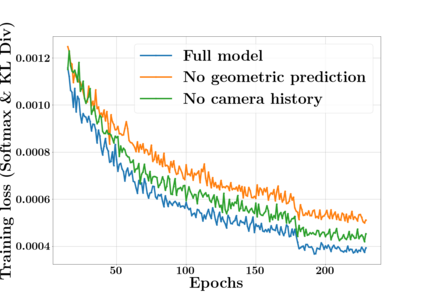
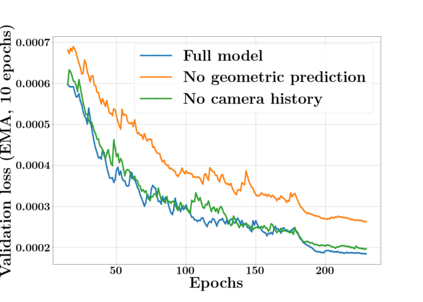
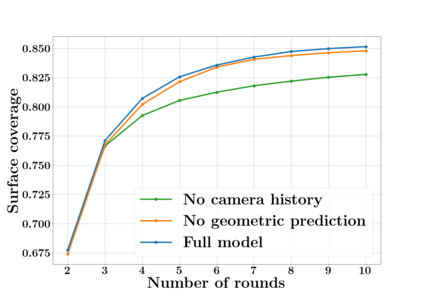
Next Best View computation (NBV) is a long-standing problem in robotics, and consists in identifying the next most informative sensor position(s) for reconstructing a 3D object or scene efficiently and accurately. Like most current methods, we consider NBV prediction from a depth sensor. Learning-based methods relying on a volumetric representation of the scene are suitable for path planning, but do not scale well with the size of the scene and have lower accuracy than methods using a surface-based representation. However, the latter constrain the camera to a small number of poses. To obtain the advantages of both representations, we show that we can maximize surface metrics by Monte Carlo integration over a volumetric representation. Our method scales to large scenes and handles free camera motion: It takes as input an arbitrarily large point cloud gathered by a depth sensor like Lidar systems as well as camera poses to predict NBV. We demonstrate our approach on a novel dataset made of large and complex 3D scenes.
翻译:下一个最佳视图计算(NBV)是机器人中长期存在的一个问题,它包括确定下一个信息最丰富的传感器位置,以便高效和准确地重建3D对象或场景。与目前大多数方法一样,我们认为NBV是从深度传感器预测的。基于对场面的体积表示的学习方法适合路径规划,但与场面的大小不相称,精确度低于使用地表表示法的方法。然而,后者将相机限制在少量外观上。为了获得两种表示的优势,我们显示我们可以通过Monte Carlo集成以体积表示的方式最大限度地利用地面测量仪。我们的方法尺度对大场景进行测量,并处理自由的摄像机运动:它吸收了由Lidar系统等深度传感器收集的任意大点云以及用于预测NBV的摄像头。我们展示了我们对由大型和复杂的3D场景组成的新数据集的方法。