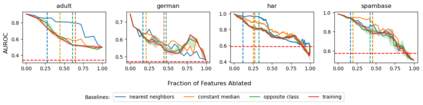
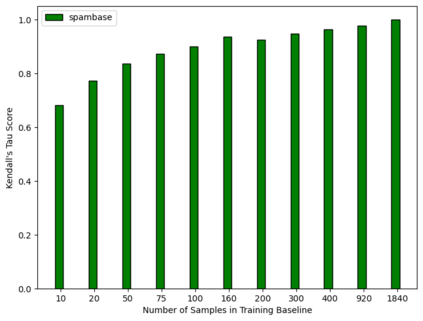
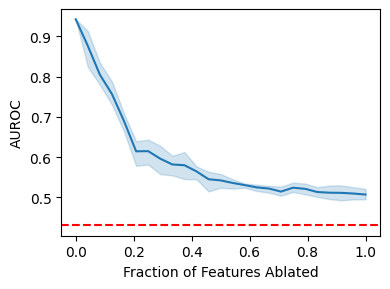
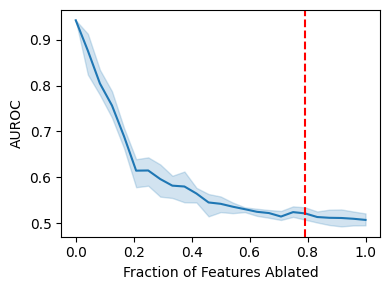
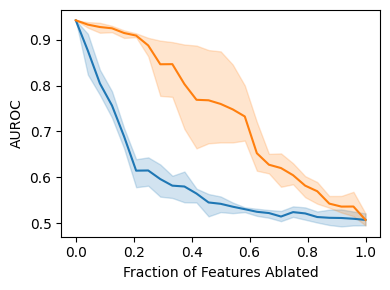
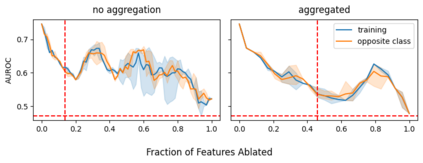
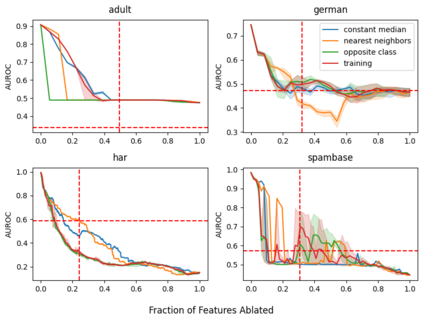
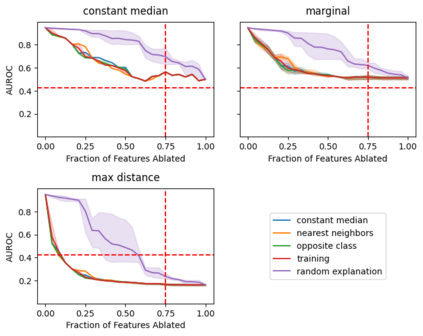
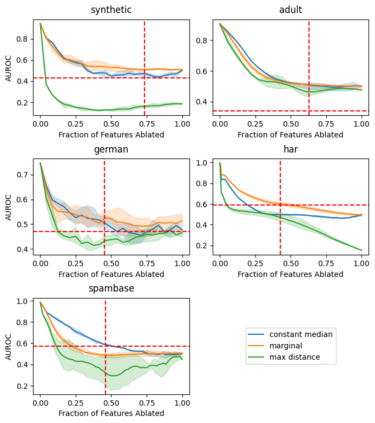
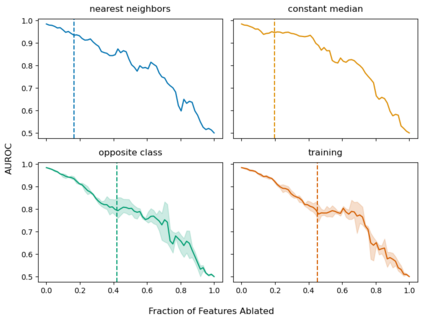
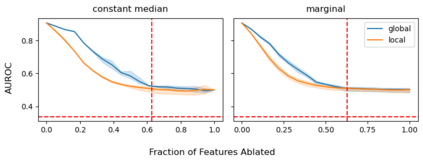
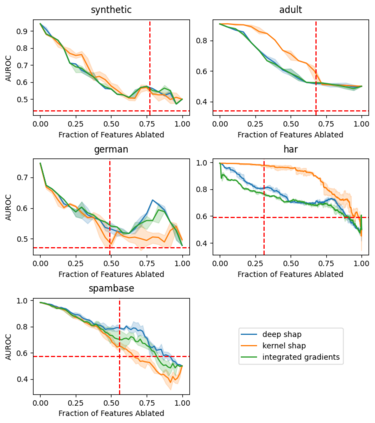
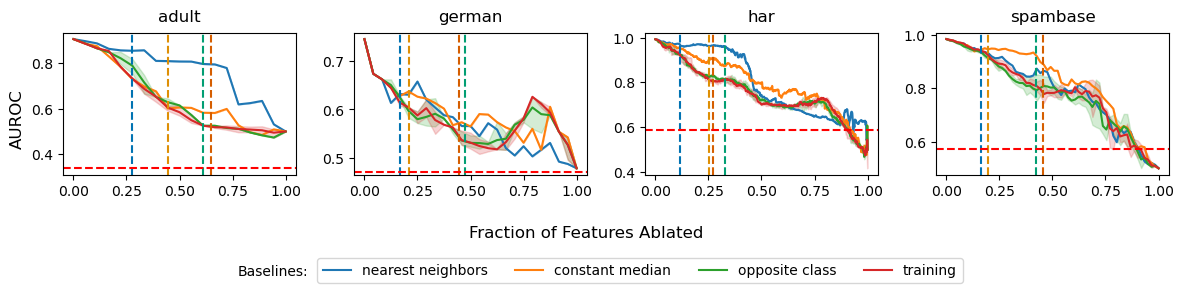
Explainable artificial intelligence (XAI) methods lack ground truth. In its place, method developers have relied on axioms to determine desirable properties for their explanations' behavior. For high stakes uses of machine learning that require explainability, it is not sufficient to rely on axioms as the implementation, or its usage, can fail to live up to the ideal. As a result, there exists active research on validating the performance of XAI methods. The need for validation is especially magnified in domains with a reliance on XAI. A procedure frequently used to assess their utility, and to some extent their fidelity, is an ablation study. By perturbing the input variables in rank order of importance, the goal is to assess the sensitivity of the model's performance. Perturbing important variables should correlate with larger decreases in measures of model capability than perturbing less important features. While the intent is clear, the actual implementation details have not been studied rigorously for tabular data. Using five datasets, three XAI methods, four baselines, and three perturbations, we aim to show 1) how varying perturbations and adding simple guardrails can help to avoid potentially flawed conclusions, 2) how treatment of categorical variables is an important consideration in both post-hoc explainability and ablation studies, and 3) how to identify useful baselines for XAI methods and viable perturbations for ablation studies.
翻译:可解释的人工智能(XAI) 方法缺乏地面真相。 方法开发者在它的位置上依靠xexom 来确定其解释行为的适当属性。 对于需要解释的机器学习的高度利害关系使用,对于机器学习需要解释的高度利害关系使用,仅仅依赖xexom 是不够的,因为执行或使用可能达不到理想。因此,存在关于验证XAI方法的性能的积极研究。在依赖XAI的域域中,验证的必要性特别扩大。经常用来评估其效用和某种程度上其忠诚性的一个程序是通缩研究。 通过按重要性等级顺序对输入变量进行扰动,我们的目标是评估模型性能的敏感性。 扰动性重要变量应当与模型能力计量的减少幅度相比,而不是扰动不太重要的特征。 虽然意图很明确,但实际执行细节对于表格数据的研究并不严格。 使用5个数据集、3 XAI 方法、4个基线和3个扰动性分析,我们的目标是表明:1) 不同易变的易变性研究如何解释和可能稳性研究如何解释AI2) 的精确性研究、简单性研究如何避免和精确性结论。