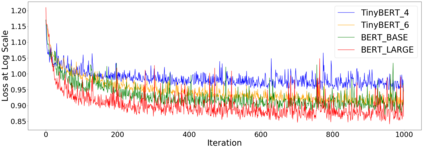
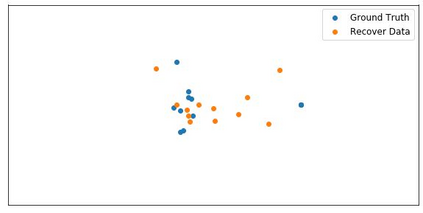
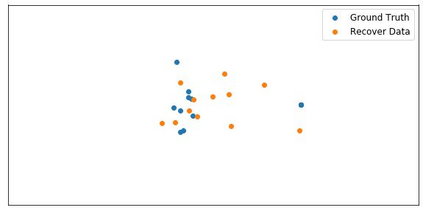
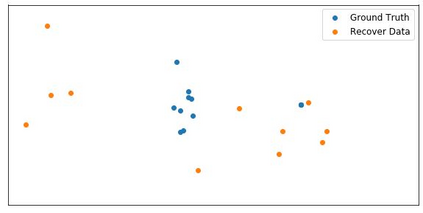
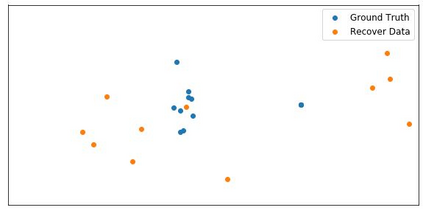
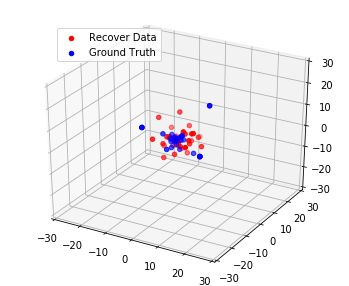
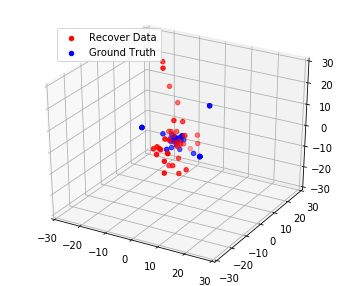
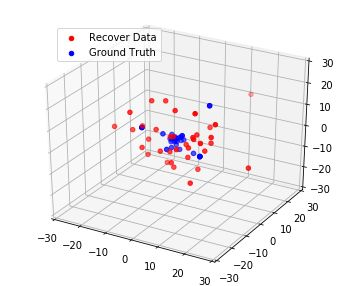
Although federated learning has increasingly gained attention in terms of effectively utilizing local devices for data privacy enhancement, recent studies show that publicly shared gradients in the training process can reveal the private training images (gradient leakage) to a third-party in computer vision. We have, however, no systematic understanding of the gradient leakage mechanism on the Transformer based language models. In this paper, as the first attempt, we formulate the gradient attack problem on the Transformer-based language models and propose a gradient attack algorithm, TAG, to reconstruct the local training data. We develop a set of metrics to evaluate the effectiveness of the proposed attack algorithm quantitatively. Experimental results on Transformer, TinyBERT$_{4}$, TinyBERT$_{6}$, BERT$_{BASE}$, and BERT$_{LARGE}$ using GLUE benchmark show that TAG works well on more weight distributions in reconstructing training data and achieves 1.5$\times$ recover rate and 2.5$\times$ ROUGE-2 over prior methods without the need of ground truth label. TAG can obtain up to 90$\%$ data by attacking gradients in CoLA dataset. In addition, TAG has a stronger adversary on large models, small dictionary size, and small input length. We hope the proposed TAG will shed some light on the privacy leakage problem in Transformer-based NLP models.
翻译:虽然联谊学习在有效利用本地设备提高数据隐私方面日益受到重视,但最近的研究表明,在培训过程中公开分享的梯度可以将私人培训图像(重大渗漏)透露给计算机视野中的第三方;然而,我们没有系统地了解基于变异器的语言模型中的梯度渗漏机制;在本文中,作为第一次尝试,我们为基于变异器的语言模型制定了梯度攻击问题,并提议了一个梯度攻击算法,即TAG,以重建当地培训数据。我们开发了一套衡量标准,以从数量上评价拟议攻击算法的有效性。关于变异器的实验结果,TinyyBER$*4}$4美元,TinyBERTinBER$6},BERT$_BASE}和BERT$LARGE} 美元。在GAG在重建培训数据方面,在以1.5美元为基数的回收率和2.5美元为基时,在此前方法上评估ROUGE-2的效益。TAAG可以获得高达90美元、TyBER$6$6$的实验结果。