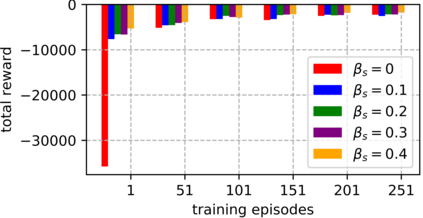
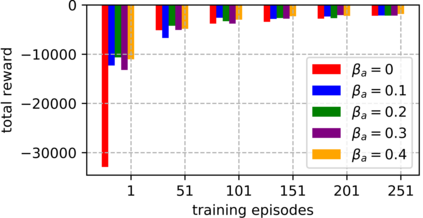
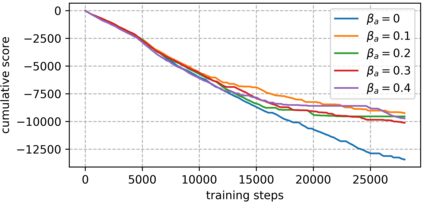
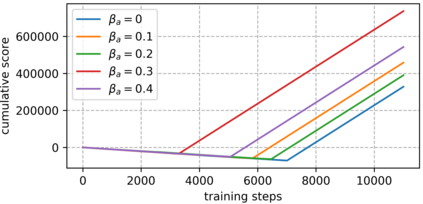
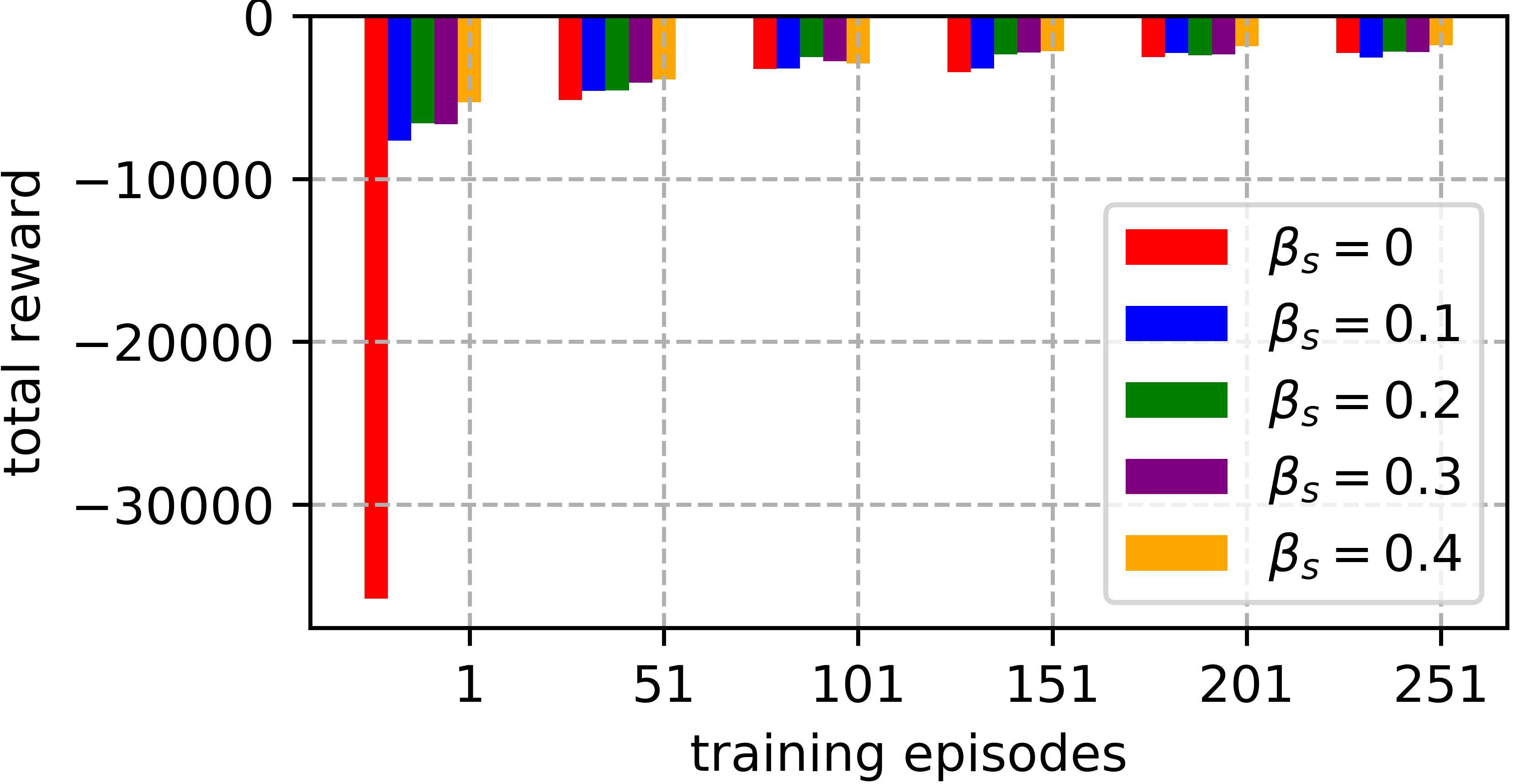
An improvement of Q-learning is proposed in this paper. It is different from classic Q-learning in that the similarity between different states and actions is considered in the proposed method. During the training, a new updating mechanism is used, in which the Q value of the similar state-action pairs are updated synchronously. The proposed method can be used in combination with both tabular Q-learning function and deep Q-learning. And the results of numerical examples illustrate that compared to the classic Q-learning, the proposed method has a significantly better performance.
翻译:本文件建议改进 " Q-学习 ",与传统的 " Q-学习 " 不同,因为在拟议方法中考虑了不同州和行动之间的相似性。在培训期间,采用了新的更新机制,对类似的州-行动对子的 " Q " 值同步更新。拟议方法可以与表格的 " Q-学习功能 " 和深层次的 " Q-学习 " 相结合使用。数字实例的结果表明,与典型的 " Q-学习 " 相比,拟议方法的绩效要好得多。