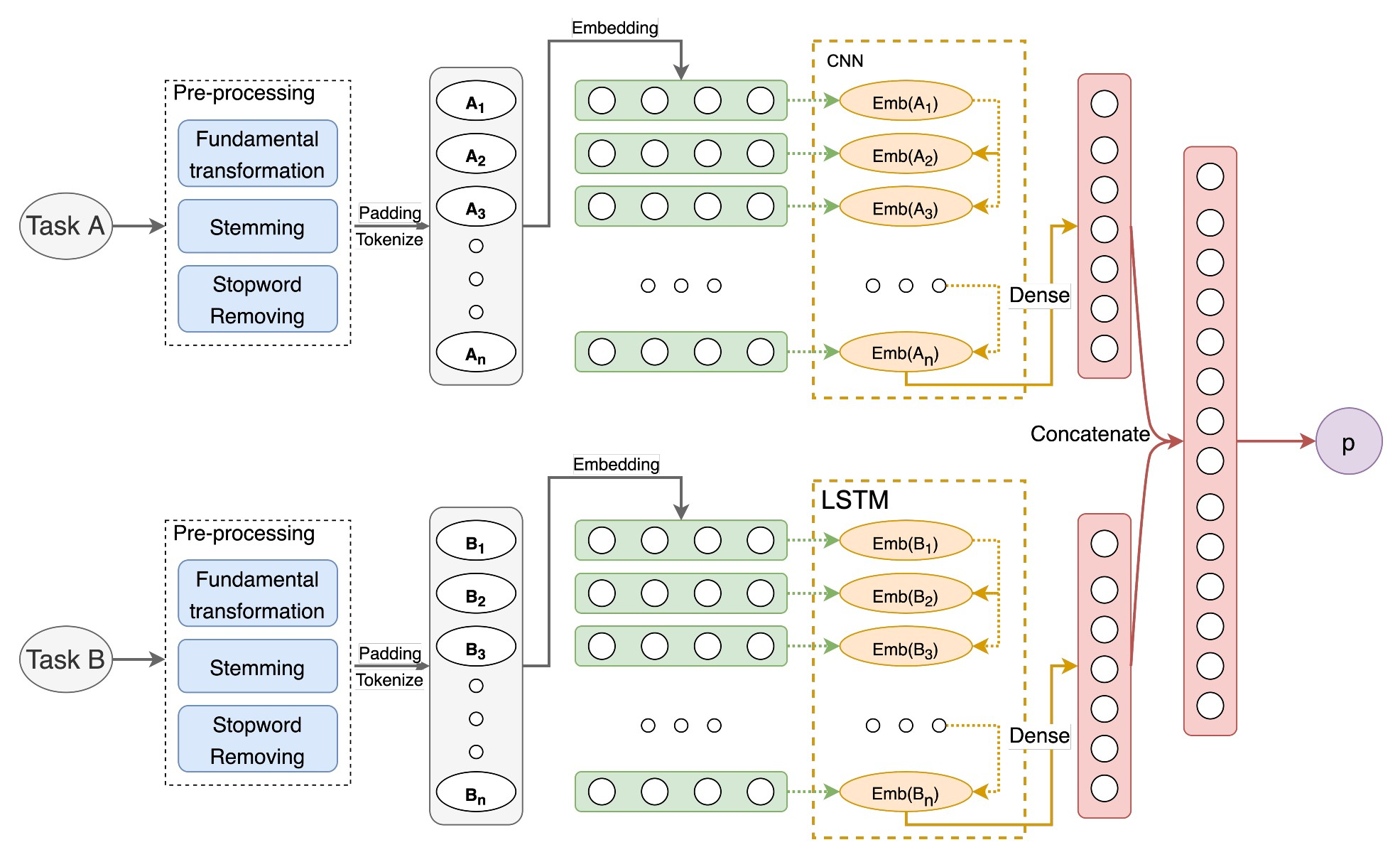
Many startups and companies worldwide have been using project management software and tools to monitor, track and manage their projects. For software projects, the number of tasks from the beginning to the end is quite a large number that sometimes takes a lot of time and effort to search and link the current task to a group of previous ones for further references. This paper proposes an efficient task dependency recommendation algorithm to suggest tasks dependent on a given task that the user has just created. We present an efficient feature engineering step and construct a deep neural network to this aim. We performed extensive experiments on two different large projects (MDLSITE from moodle.org and FLUME from apache.org) to find the best features in 28 combinations of features and the best performance model using two embedding methods (GloVe and FastText). We consider three types of models (GRU, CNN, LSTM) using Accuracy@K, MRR@K, and Recall@K (where K = 1, 2, 3, and 5) and baseline models using traditional methods: TF-IDF with various matching score calculating such as cosine similarity, Euclidean distance, Manhattan distance, and Chebyshev distance. After many experiments, the GloVe Embedding and CNN model reached the best result in our dataset, so we chose this model as our proposed method. In addition, adding the time filter in the post-processing step can significantly improve the recommendation system's performance. The experimental results show that our proposed method can reach 0.2335 in Accuracy@1 and MRR@1 and 0.2011 in Recall@1 of dataset FLUME. With the MDLSITE dataset, we obtained 0.1258 in Accuracy@1 and MRR@1 and 0.1141 in Recall@1. In the top 5, our model reached 0.3040 in Accuracy@5, 0.2563 MRR@5, and 0.2651 Recall@5 in FLUME. In the MDLSITE dataset, our model got 0.5270 Accuracy@5, 0.2689 MRR@5, and 0.2651 Recall@5.
翻译:世界各地许多创业者和公司一直在使用项目管理软件和工具来监测、跟踪和管理项目。 对于软件项目,从开始到结束的任务数量相当多,有时需要花费大量的时间和精力来搜索当前任务并将其与先前任务组连接,以便进一步参考。本文提出高效的任务依赖性建议算法,以建议取决于用户刚刚创建的某个特定任务。我们展示了一个高效的功能特征工程步骤,并为此目的构建了一个深层神经网络。我们在两个不同的大型项目(MDLSITE from demalle.org 和 FLUME from apache.org)上进行了广泛的实验,以在28个功能组合和最佳性模型中找到最佳功能(GloVe和FastText)。我们考虑三种模式(GRU、CNN、LSTM)、Acread@K和Recall@K(K=1、2、3和5)模型中,我们获得了KFlevreadreadrequest 以及使用传统方法:TFT-IDFDF, 和各种匹配得分数分计算结果,例如Ceurate、Eloy、Eceldealde、Eudealdeal、Eudealdealdeal、Redrodeal、Seal、我们在Slodeal、我们用Slate、我们最远的Slode、我们最远的Sde、我们最远的S、最远的S、我们的数据方法中显示的Sl、最远的S、最短的S、我们的数据方法、我们用的方法、最短的Fl、最短的Fl、在这种方法中,在Slation、我们的数据方法中可以显示我们用。