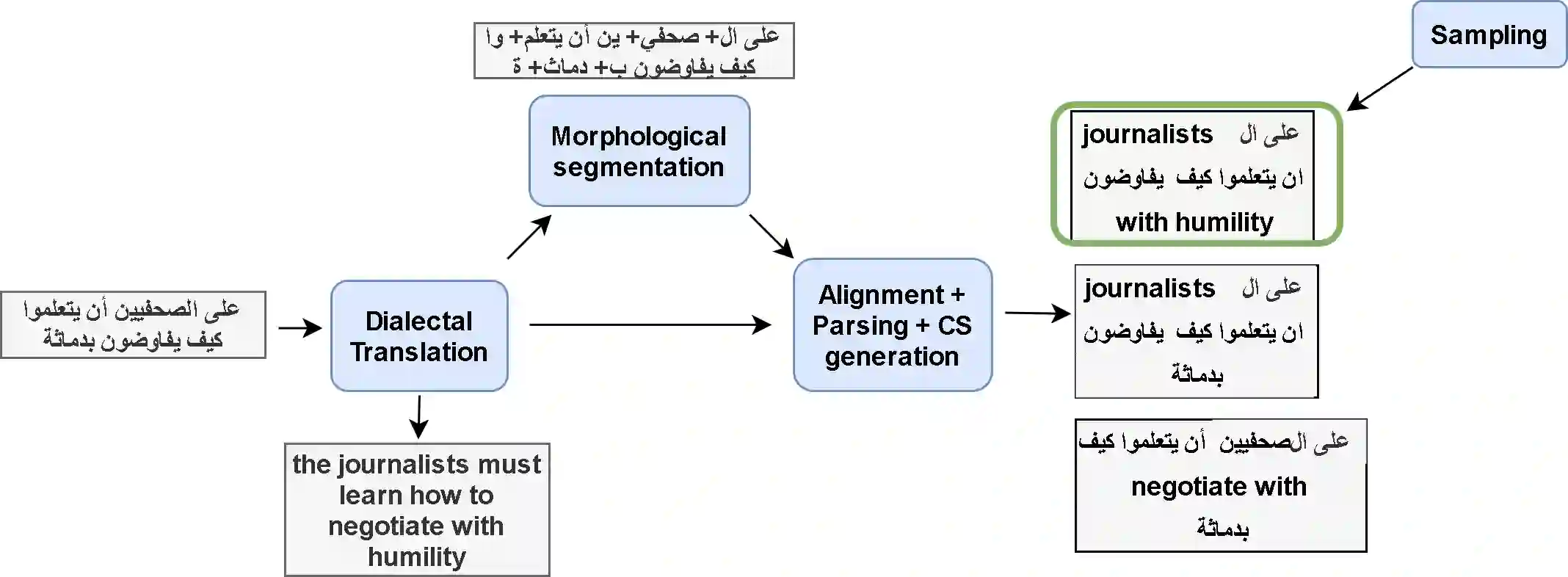
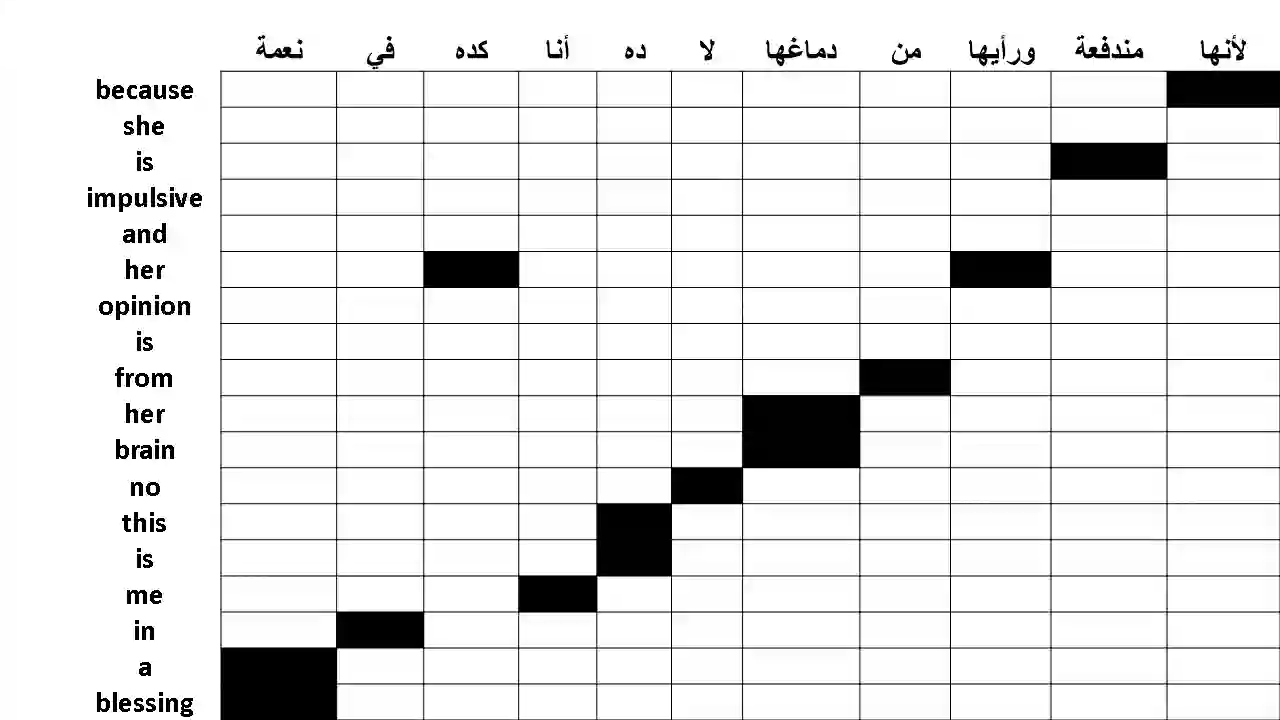
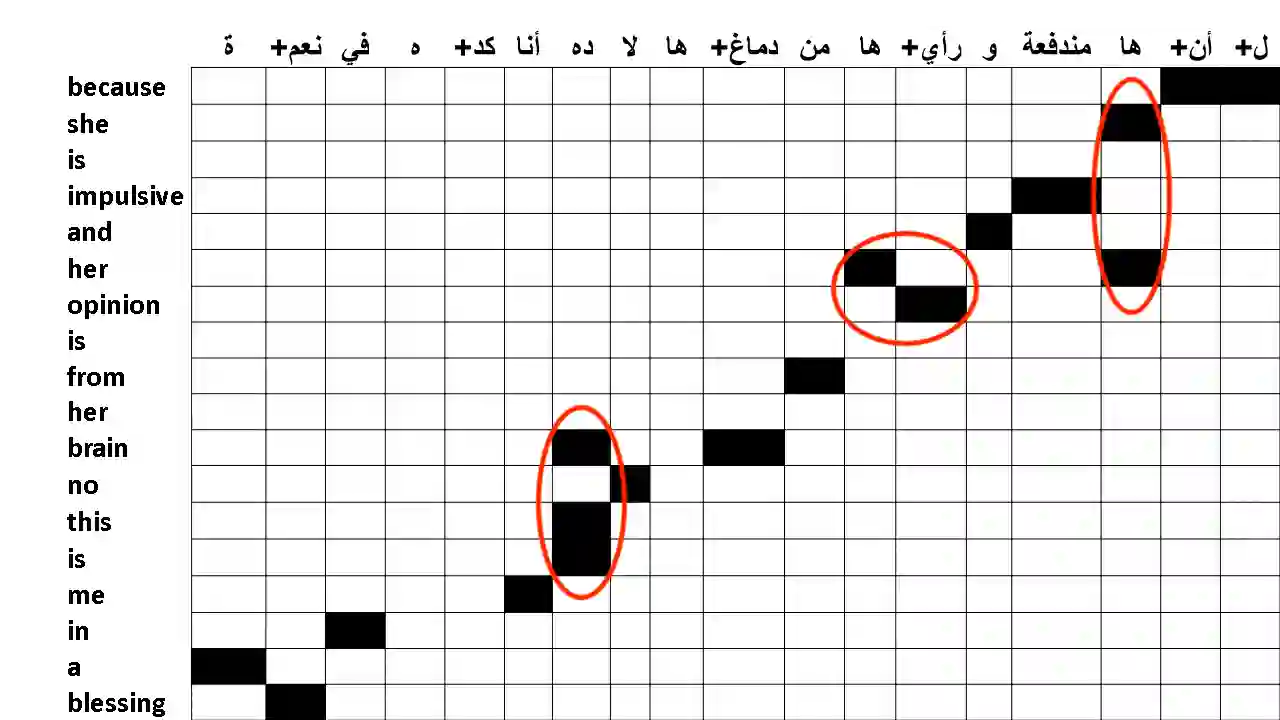
The pervasiveness of intra-utterance Code-switching (CS) in spoken content has enforced ASR systems to handle mixed input. Yet, designing a CS-ASR has many challenges, mainly due to the data scarcity, grammatical structure complexity, and mismatch along with unbalanced language usage distribution. Recent ASR studies showed the predominance of E2E-ASR using multilingual data to handle CS phenomena with little CS data. However, the dependency on the CS data still remains. In this work, we propose a methodology to augment the monolingual data for artificially generating spoken CS text to improve different speech modules. We based our approach on Equivalence Constraint theory while exploiting aligned translation pairs, to generate grammatically valid CS content. Our empirical results show a relative gain of 29-34 % in perplexity and around 2% in WER for two ecological and noisy CS test sets. Finally, the human evaluation suggests that 83.8% of the generated data is acceptable to humans.
翻译:口语内容的内地代码转换(CS)的普及性迫使ASR系统处理混合输入。然而,设计CS-ASR有许多挑战,主要原因是数据稀缺、语法结构复杂和不匹配以及语言使用分布不平衡。最近的ASR研究表明,E2E-ASR使用多语种数据处理CS现象,而CS数据很少。然而,对CS数据的依赖性仍然存在。在这项工作中,我们提议了一种方法,用于增加单语种数据,用于人工生成口语 CS 文本,以改善不同的语音模块。我们以等同约束理论为基础,同时利用对齐的翻译对配,生成语法上有效的 CS内容。我们的经验结果表明,在两个生态和噪音CS测试组中,在WER中相对增加29-34%,在WER中增加2%左右。最后,人类评价表明,产生的数据中有83.8%是可以接受的。