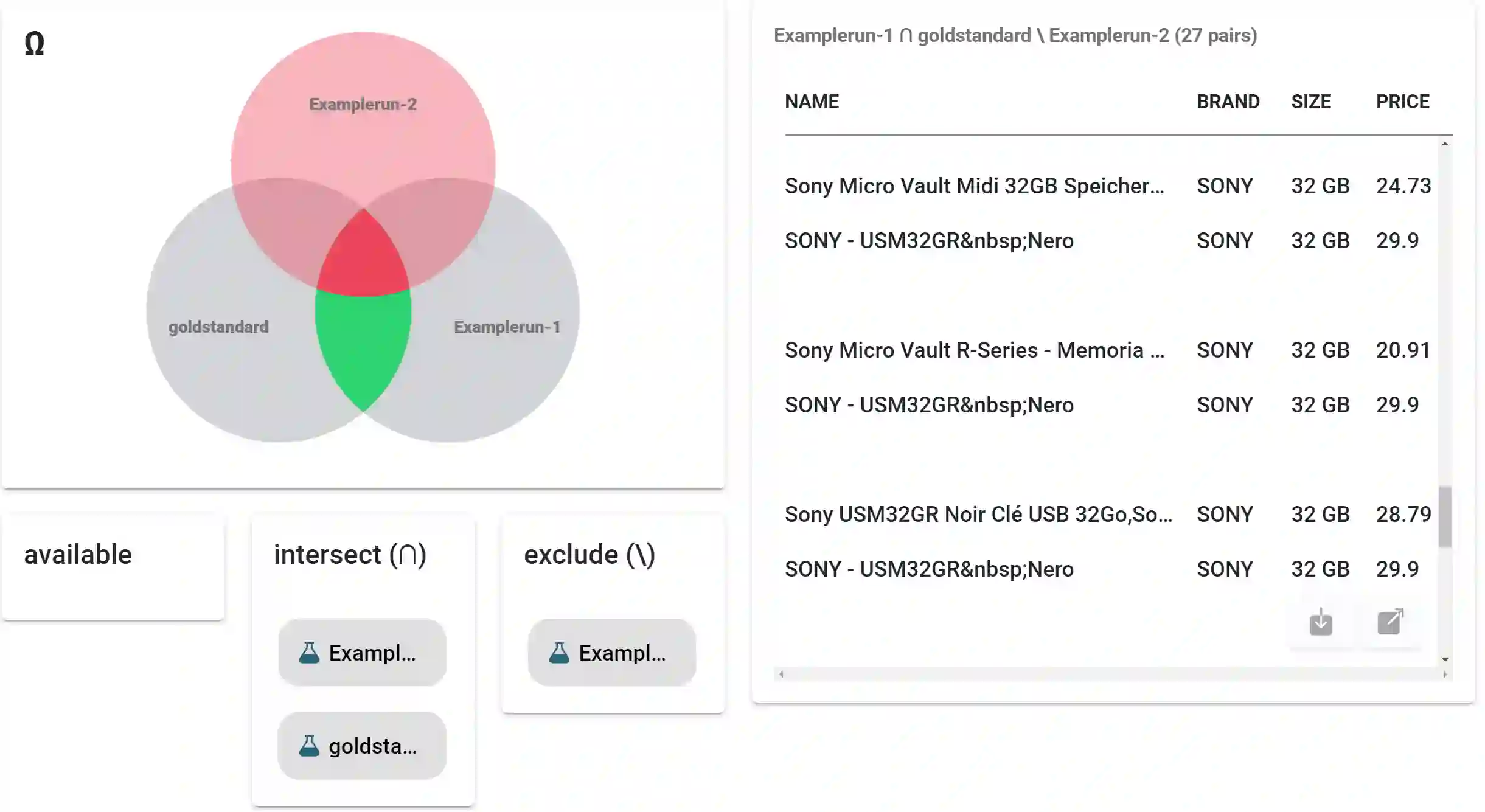
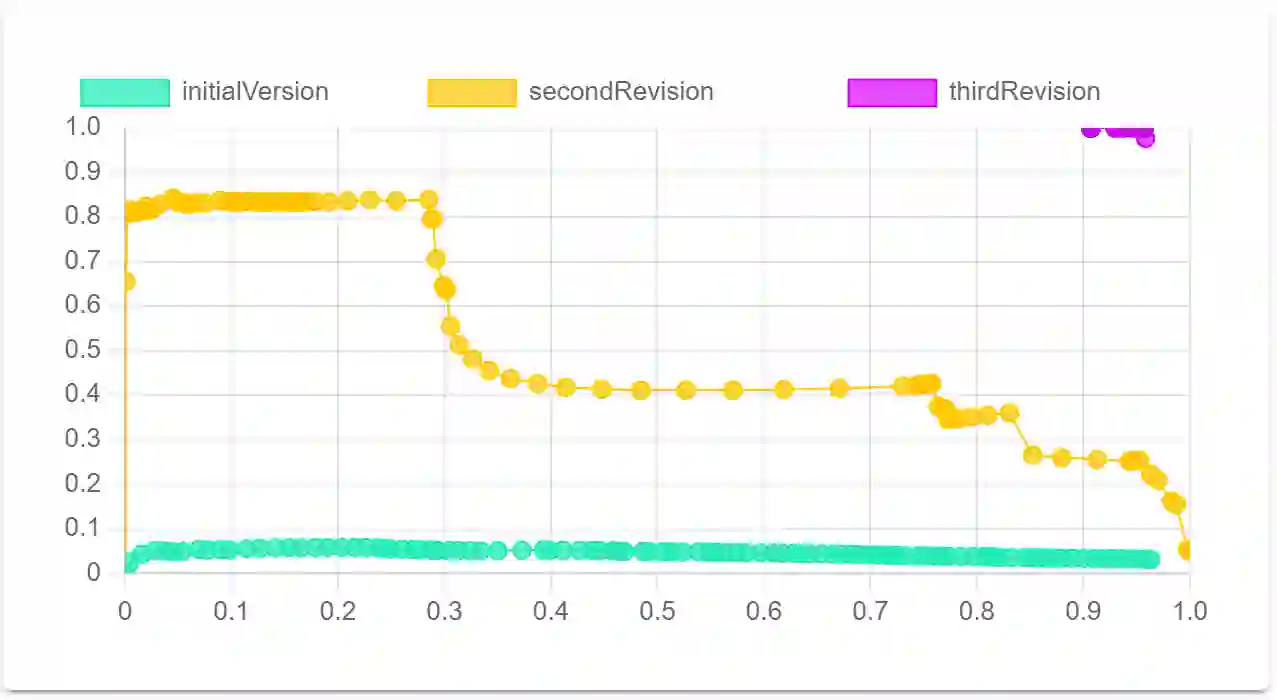
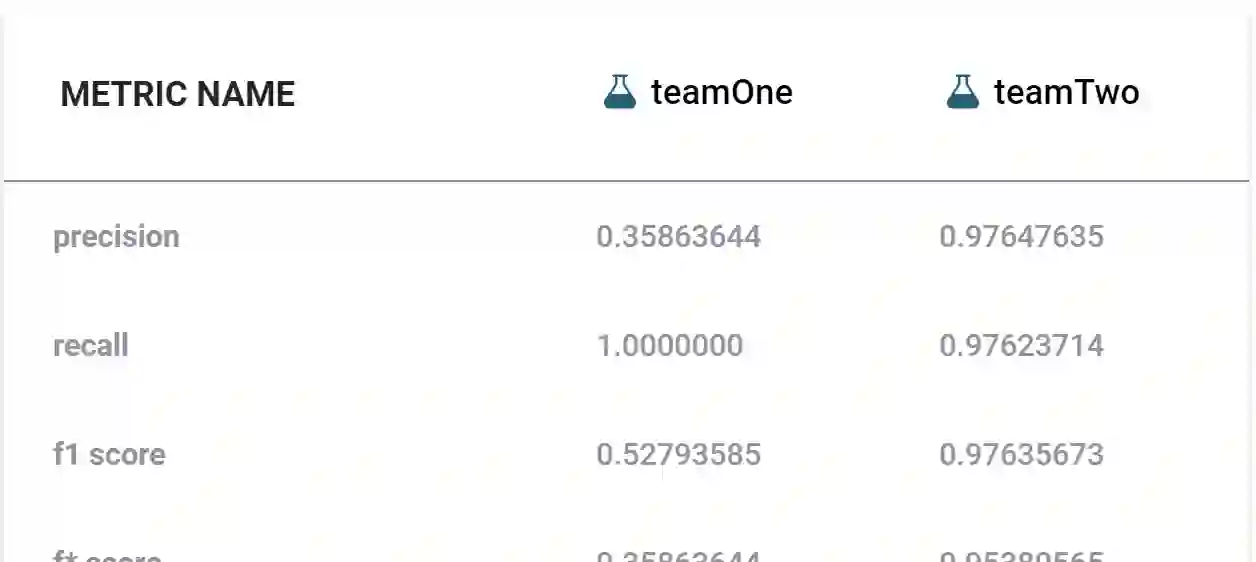
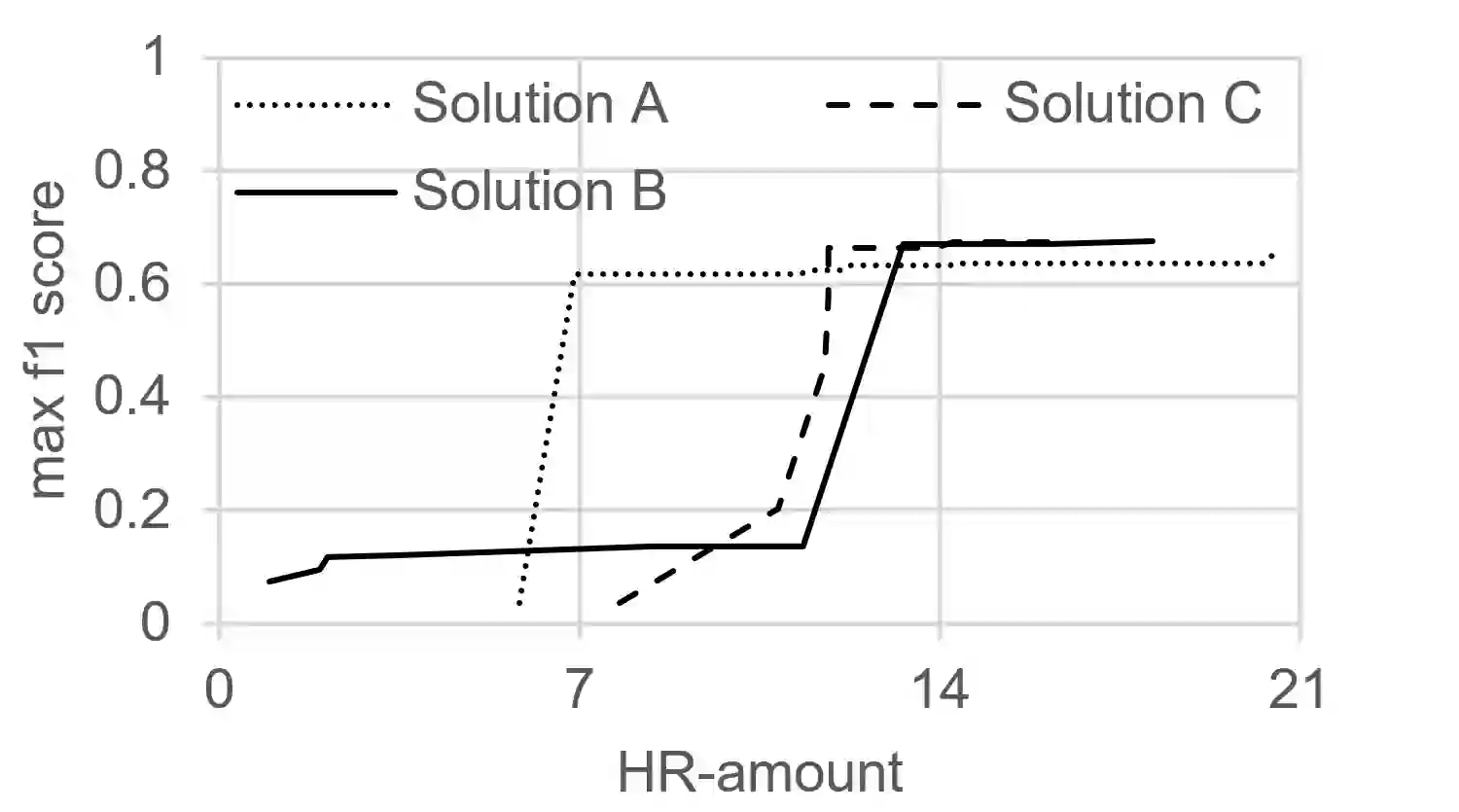
"Bad" data has a direct impact on 88% of companies, with the average company losing 12% of its revenue due to it. Duplicates - multiple but different representations of the same real-world entities - are among the main reasons for poor data quality. Therefore, finding and configuring the right deduplication solution is essential. Various data matching benchmarks exist which address this issue. However, many of them focus on the quality of matching results and neglect other important factors, such as business requirements. Additionally, they often do not specify how to explore benchmark results, which helps understand matching solution behavior. To address this gap between the mere counting of record pairs vs. a comprehensive means to evaluate data matching approaches, we present the benchmark platform Frost. Frost combines existing benchmarks, established quality metrics, a benchmark dimension for soft KPIs, and techniques to systematically explore and understand matching results. Thus, it can be used to compare multiple matching solutions regarding quality, usability, and economic aspects, but also to compare multiple runs of the same matching solution for understanding its behavior. Frost is implemented and published in the open-source application Snowman, which includes the visual exploration of matching results.
翻译:“ 错误” 数据直接影响到88%的公司,平均公司收入的12%因此损失了12%。 重复—— 相同真实世界实体的多重但不同的表现—— 是数据质量差的主要原因。 因此, 找到和配置正确的解析解决方案至关重要 。 各种数据匹配基准可以解决这个问题。 但是, 其中许多数据匹配基准侧重于匹配结果的质量, 忽视其他重要因素, 如商业要求 。 此外, 它们往往没有具体说明如何探索基准结果, 这有助于理解匹配解决方案的行为。 为了解决仅仅计算记录对对对与评估数据匹配方法的全面方法之间的差距, 我们介绍了基准平台Frost。 Frost 将现有的基准、 建立的质量指标、 软的KPIs的基准维度以及系统探索和理解匹配结果的技术结合起来。 因此, 它可以用来比较质量、 可使用性和经济方面的多重匹配解决方案, 但也用来比较同一匹配解决方案的多重运行量, 以了解其行为 。 Frostowman 应用软件中实施并公布, 包括直观匹配结果的探索。