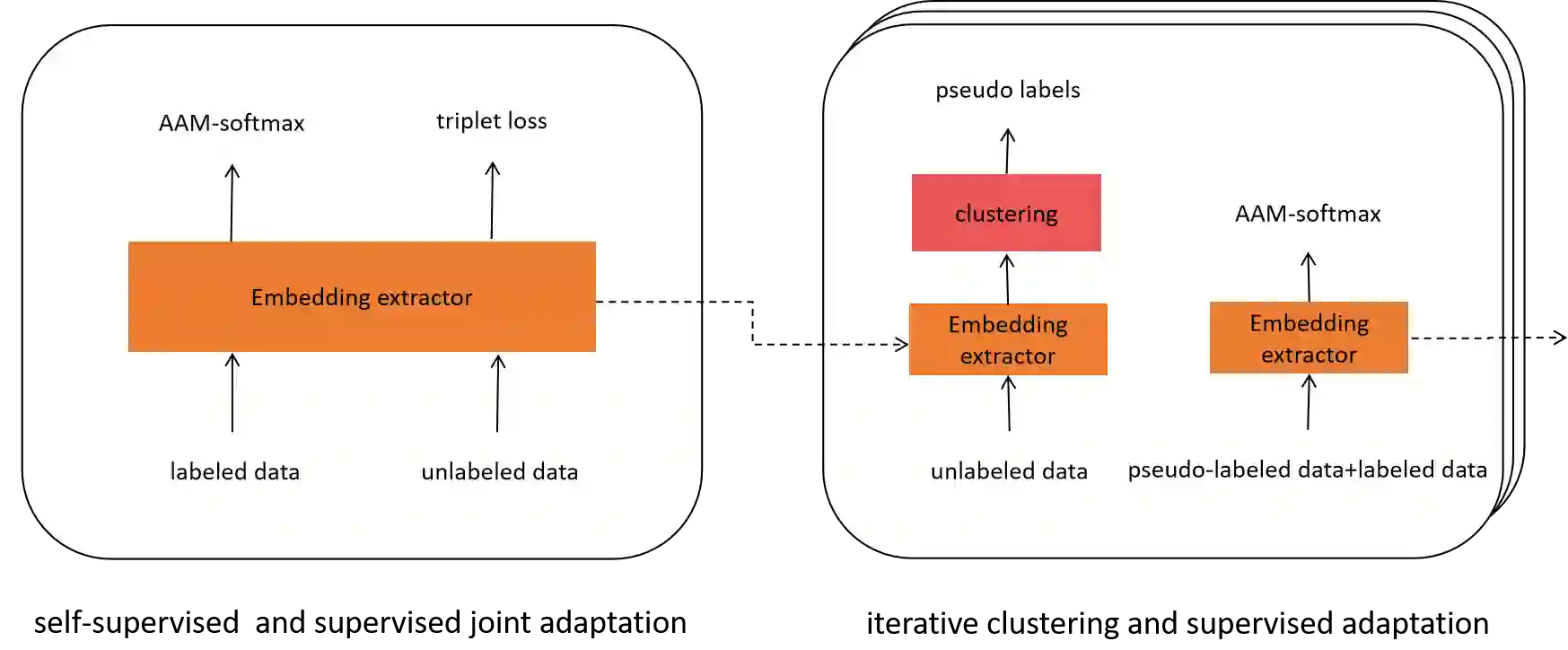
In this technical report, we describe the Royalflush submissions for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our submissions contain track 1, which is for supervised speaker verification and track 3, which is for semi-supervised speaker verification. For track 1, we develop a powerful U-Net-based speaker embedding extractor with a symmetric architecture. The proposed system achieves 2.06% in EER and 0.1293 in MinDCF on the validation set. Compared with the state-of-the-art ECAPA-TDNN, it obtains a relative improvement of 20.7% in EER and 22.70% in MinDCF. For track 3, we employ the joint training of source domain supervision and target domain self-supervision to get a speaker embedding extractor. The subsequent clustering process can obtain target domain pseudo-speaker labels. We adapt the speaker embedding extractor using all source and target domain data in a supervised manner, where it can fully leverage both domain information. Moreover, clustering and supervised domain adaptation can be repeated until the performance converges on the validation set. Our final submission is a fusion of 10 models and achieves 7.75% EER and 0.3517 MinDCF on the validation set.
翻译:在本技术报告中,我们描述了Royalflush提交VoxCeleb议长承认挑战2022(VoxSRC-22)。我们的呈件包含第1轨,用于监督演讲者核查,第3轨,用于半监督演讲者核查。第1轨,我们开发了强大的U-Net基演讲者嵌入提取器,并配有对称结构。拟议的系统在验证集中实现了2.06%的EER和0.1293的MinDCF。与最先进的ECAPA-TDNN相比,它相对改进了20.7%的EER和22.70%的MinDCF。关于第3轨,我们采用对源域监督的联合培训和目标域自我监督的联合培训,以获得发言者嵌入式。随后的组合进程可以获得目标域化伪发言人标签。我们用所有源和目标域数据对发言者嵌入的定位器进行了调整,从而能够充分利用域信息。此外,组合和监管的域适应可以重复到验证集集的性工作之前。我们的最后呈件是10个ER 0.175模型的MER 0.15和0.175的确认。