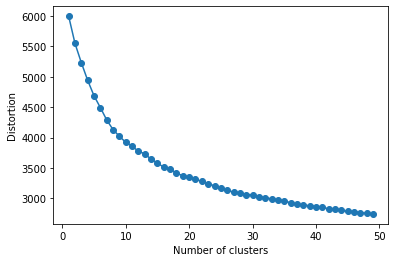
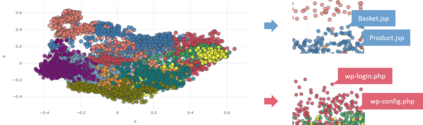
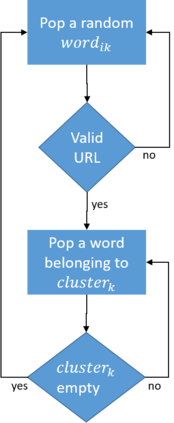
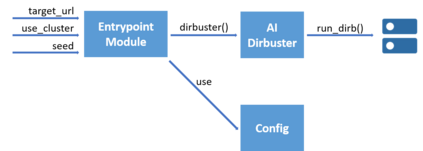
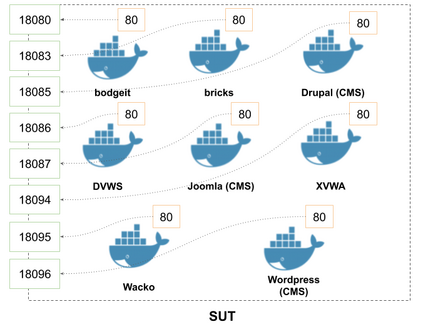
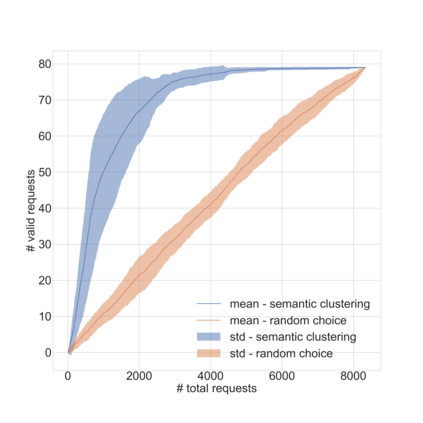
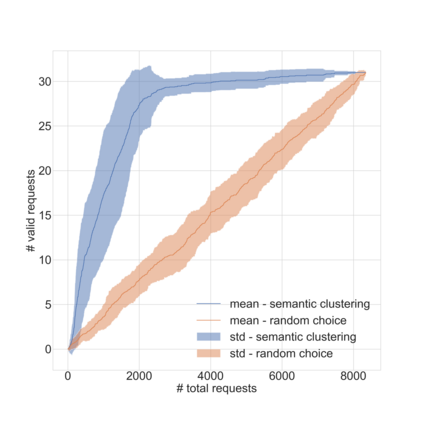
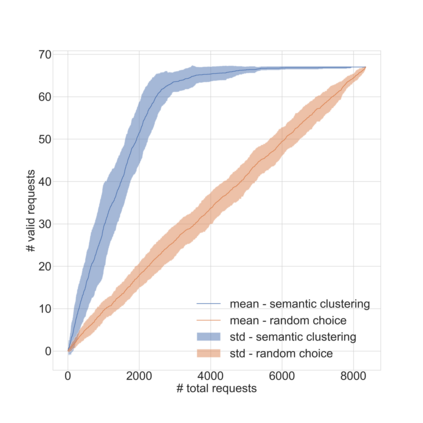
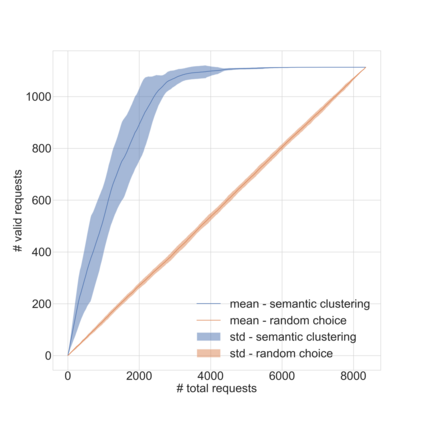
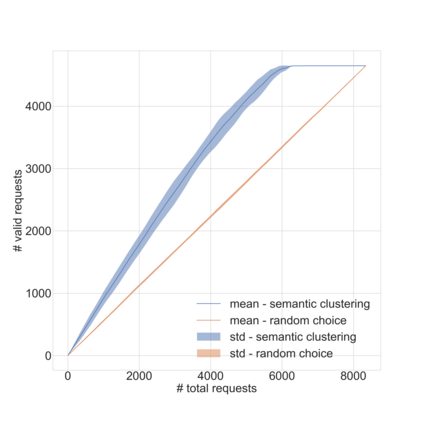
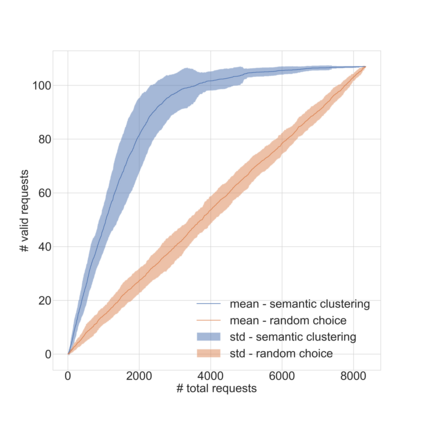
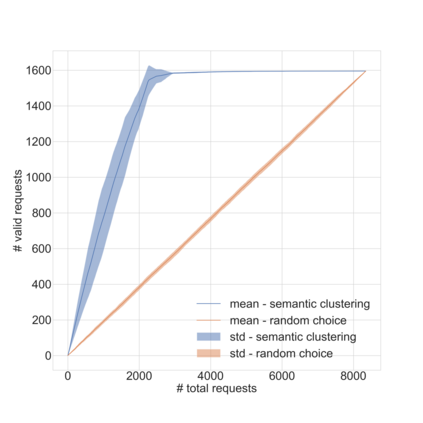
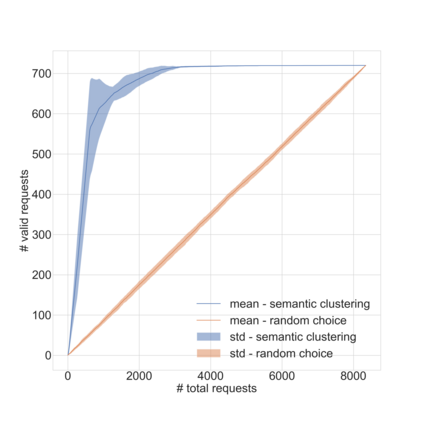
Dirbusting is a technique used to brute force directories and file names on web servers while monitoring HTTP responses, in order to enumerate server contents. Such a technique uses lists of common words to discover the hidden structure of the target website. Dirbusting typically relies on response codes as discovery conditions to find new pages. It is widely used in web application penetration testing, an activity that allows companies to detect websites vulnerabilities. Dirbusting techniques are both time and resource consuming and innovative approaches have never been explored in this field. We hence propose an advanced technique to optimize the dirbusting process by leveraging Artificial Intelligence. More specifically, we use semantic clustering techniques in order to organize wordlist items in different groups according to their semantic meaning. The created clusters are used in an ad-hoc implemented next-word intelligent strategy. This paper demonstrates that the usage of clustering techniques outperforms the commonly used brute force methods. Performance is evaluated by testing eight different web applications. Results show a performance increase that is up to 50% for each of the conducted experiments.
翻译:Dirbusing是一种用来在监测 HTTP 回复时在网络服务器上强行使用目录和文件名称的技术,目的是列出服务器内容。这种技术使用通用词汇列表来发现目标网站的隐藏结构。 Dirbusing通常依赖响应代码作为发现新页面的发现条件。它被广泛用于网络应用渗透测试,允许公司检测网站脆弱性。 Drusing 技术既耗时又耗资资源,在这方面从未探索过创新方法。因此,我们提出一种先进的技术,通过利用人工智能优化 dirbusing 进程。更具体地说,我们使用语义组合技术来组织不同组的单词列表项目,以其语义意义为根据。 创建的组群用于实施下一个语言智能战略的ad-hoc 。 本文表明,集集技术的使用超过了常用的粗力方法。 通过测试八个不同的网络应用程序来评估绩效。 结果显示,每次实验的性能提高幅度高达50%。