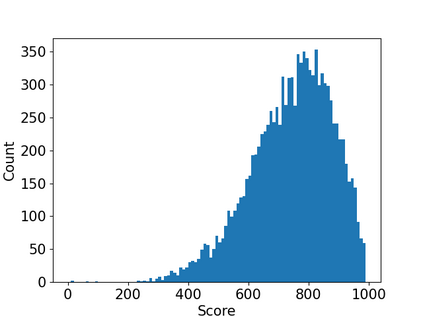
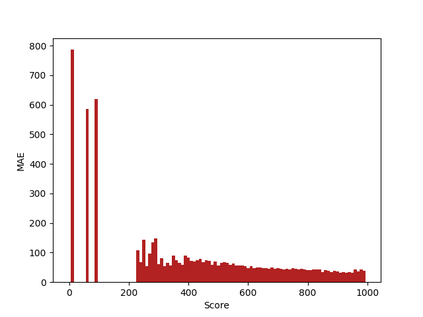
The needs for precisely estimating a student's academic performance have been emphasized with an increasing amount of attention paid to Intelligent Tutoring System (ITS). However, since labels for academic performance, such as test scores, are collected from outside of ITS, obtaining the labels is costly, leading to label-scarcity problem which brings challenge in taking machine learning approaches for academic performance prediction. To this end, inspired by the recent advancement of pre-training method in natural language processing community, we propose DPA, a transfer learning framework with Discriminative Pre-training tasks for Academic performance prediction. DPA pre-trains two models, a generator and a discriminator, and fine-tunes the discriminator on academic performance prediction. In DPA's pre-training phase, a sequence of interactions where some tokens are masked is provided to the generator which is trained to reconstruct the original sequence. Then, the discriminator takes an interaction sequence where the masked tokens are replaced by the generator's outputs, and is trained to predict the originalities of all tokens in the sequence. Compared to the previous state-of-the-art generative pre-training method, DPA is more sample efficient, leading to fast convergence to lower academic performance prediction error. We conduct extensive experimental studies on a real-world dataset obtained from a multi-platform ITS application and show that DPA outperforms the previous state-of-the-art generative pre-training method with a reduction of 4.05% in mean absolute error and more robust to increased label-scarcity.
翻译:精确估计学生学术成绩的需要得到了强调,对智能教学系统(ITS)的关注程度越来越高。然而,由于从ITS外部收集了测试分等学术成绩标签,因此标签成本昂贵,导致标签刺痕问题,在采用机器学习方法进行学术业绩预测方面带来挑战。为此,由于在自然语言处理界最近推进了培训前方法,我们建议政治部建立一个转移学习框架,为学术业绩预测提供一个有差异性的培训前任务的培训前任务。政治部前两个模型,一个发电机和一个导师,微调学术业绩预测的导师。在政治部的培训前阶段,向接受过重建原始序列培训的发电机提供一些象征的连带问题。随后,由于在自然语言处理界,我们建议采用一个互动序列,将隐性标志替换为预示牌,并用来预测序列中的所有标志的原始性。与先前的状态前两个模型,即一个生成和导师的稳健的两种模型相比,一个从先前的基因趋同式的升级方法,一个比以往的系统前阶段,一个快速的实验性模型学前方法,即演示前的演示式数据学前方法,从一个比差式数据学前的方法,从一个比差式,一个比差式数据学前的方法,从一个更高的方法到演示式的快速地学前的方法,一个比制的磨制式的磨制的磨制式方法,在政治部。