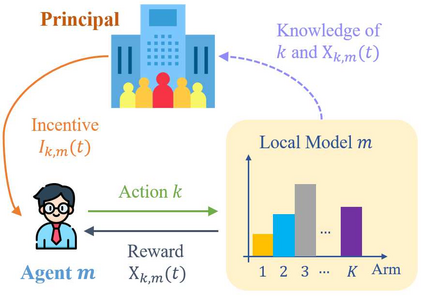
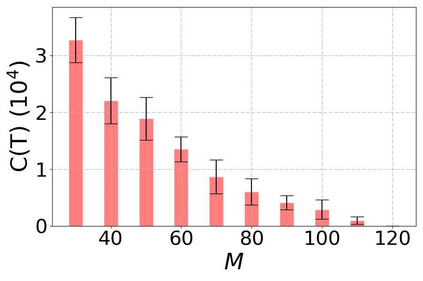
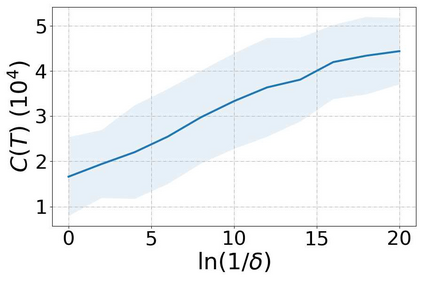
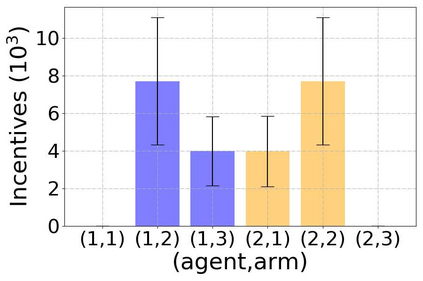
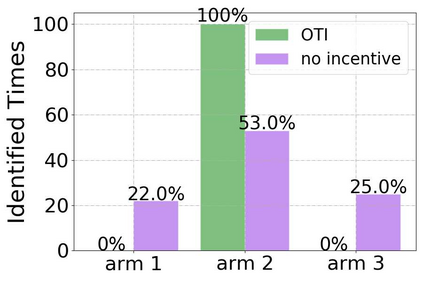
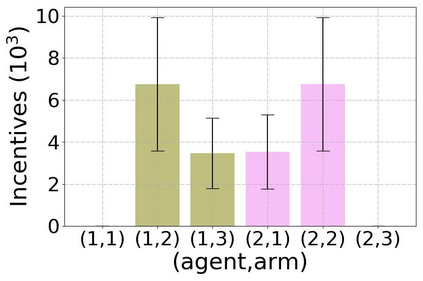
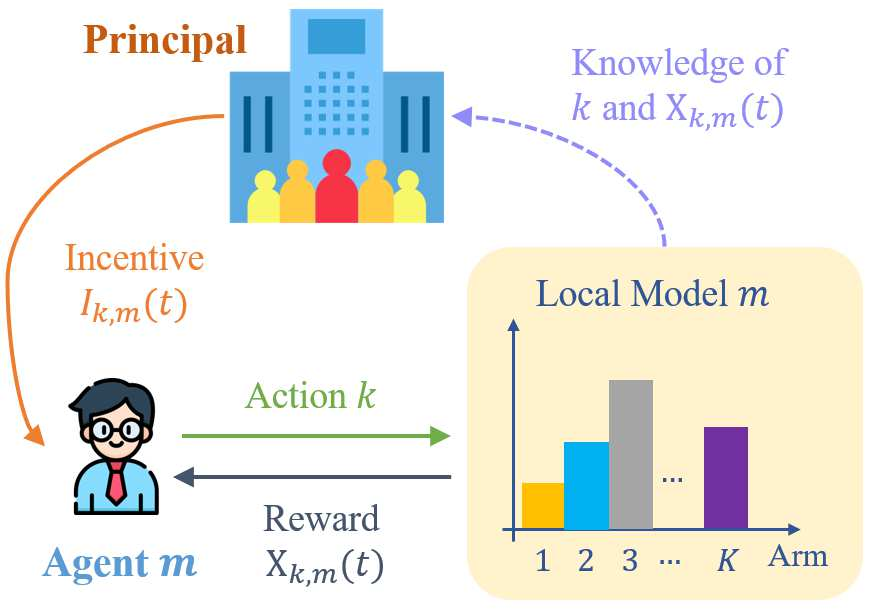
Incentivized exploration in multi-armed bandits (MAB) has witnessed increasing interests and many progresses in recent years, where a principal offers bonuses to agents to do explorations on her behalf. However, almost all existing studies are confined to temporary myopic agents. In this work, we break this barrier and study incentivized exploration with multiple and long-term strategic agents, who have more complicated behaviors that often appear in real-world applications. An important observation of this work is that strategic agents' intrinsic needs of learning benefit (instead of harming) the principal's explorations by providing "free pulls". Moreover, it turns out that increasing the population of agents significantly lowers the principal's burden of incentivizing. The key and somewhat surprising insight revealed from our results is that when there are sufficiently many learning agents involved, the exploration process of the principal can be (almost) free. Our main results are built upon three novel components which may be of independent interest: (1) a simple yet provably effective incentive-provision strategy; (2) a carefully crafted best arm identification algorithm for rewards aggregated under unequal confidences; (3) a high-probability finite-time lower bound of UCB algorithms. Experimental results are provided to complement the theoretical analysis.
翻译:近些年来,多武装强盗(MAB)的激励型探索活动日益受到关注,并取得了许多进展。 近几年来,在多武装强盗(MAB)的激励型探索活动中,利益和许多进展日益增长,本金本金本金本金为代表她进行勘探活动提供了奖金。然而,几乎所有现有研究都局限于临时的近视代理人。在这项工作中,我们打破了这一障碍,研究与多重和长期战略代理人进行激励型探索,这些代理人的行为往往在现实世界应用中出现更为复杂的行为。我们的主要成果是建立在三个可能具有独立兴趣的新构件上:(1) 简单而有效的激励性提供战略;(2) 谨慎地为在不平等信任下汇总的奖赏设计出最佳武器识别算法;(3) 高概率和令人惊讶地发现,从我们的成果中揭示的关键和令人惊讶的洞察力是,当参与的众多学习代理人参与时,本金本金的探索过程(几乎)是免费的。我们的主要成果是建立在三个可能具有独立兴趣的新构件上:(1) 简单而又有效的激励型提供战略;(2) 仔细设计了在不均等信任下进行高层次的实验性分析。