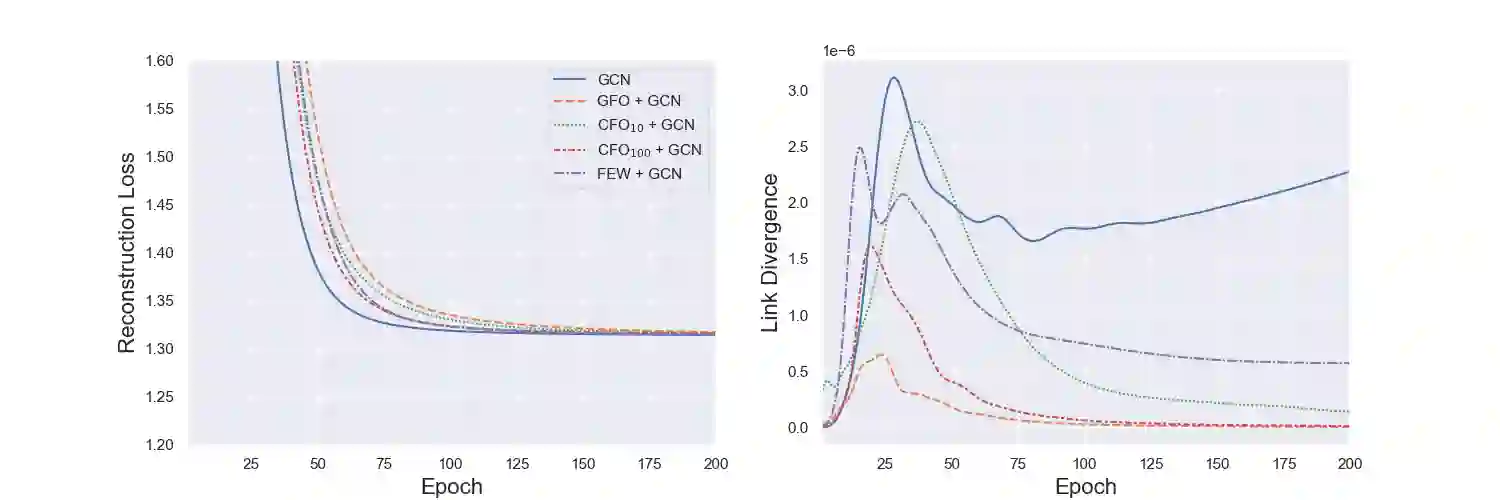
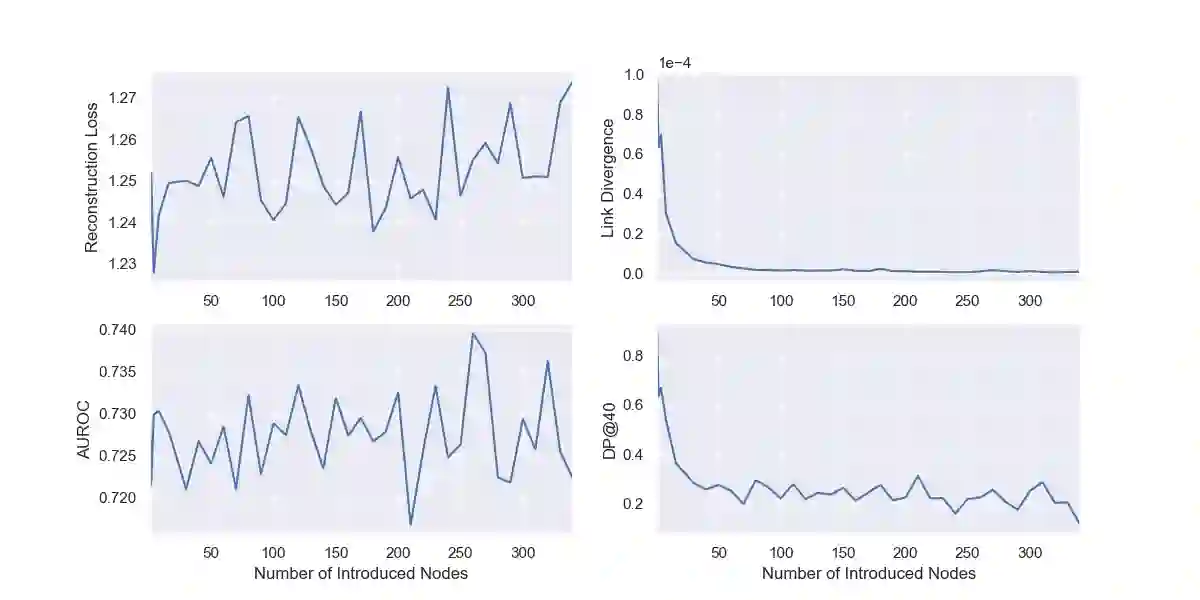
As machine learning becomes more widely adopted across domains, it is critical that researchers and ML engineers think about the inherent biases in the data that may be perpetuated by the model. Recently, many studies have shown that such biases are also imbibed in Graph Neural Network (GNN) models if the input graph is biased. In this work, we aim to mitigate the bias learned by GNNs through modifying the input graph. To that end, we propose FairMod, a Fair Graph Modification methodology with three formulations: the Global Fairness Optimization (GFO), Community Fairness Optimization (CFO), and Fair Edge Weighting (FEW) models. Our proposed models perform either microscopic or macroscopic edits to the input graph while training GNNs and learn node embeddings that are both accurate and fair under the context of link recommendations. We demonstrate the effectiveness of our approach on four real world datasets and show that we can improve the recommendation fairness by several factors at negligible cost to link prediction accuracy.
翻译:随着机器学习在各个领域被广泛采用,研究人员和ML工程师必须思考模型可能延续的数据的内在偏差。最近,许多研究显示,如果输入图有偏差,这种偏差也包含在图形神经网络模型中。在这项工作中,我们的目标是通过修改输入图来减少GNN所学的偏差。为此,我们提出FairMod, 公平图修改方法,有三种配方:全球公平优化(GFO)、社区公平最佳化(CFO)和公平环境观察(FEW)模型。我们提议的模型在对输入图进行微观或宏观编辑的同时,培训GNNMs并学习在链接建议中准确和公允的节点嵌入。我们展示了我们在四个真实世界数据集上的做法的有效性,并表明我们可以以微不足道的成本通过若干因素改进建议公平性,将预测准确性联系起来。