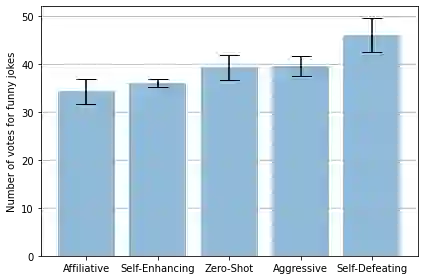
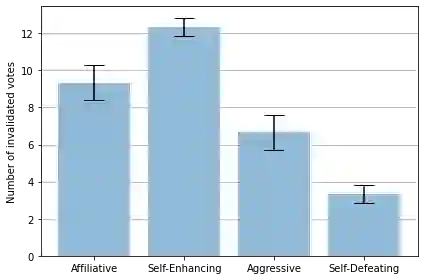
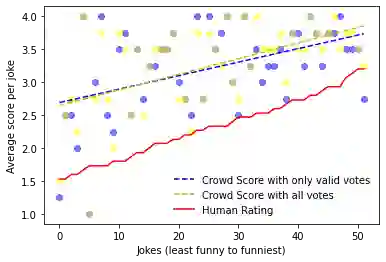
This paper presents the Crowd Score, a novel method to assess the funniness of jokes using large language models (LLMs) as AI judges. Our method relies on inducing different personalities into the LLM and aggregating the votes of the AI judges into a single score to rate jokes. We validate the votes using an auditing technique that checks if the explanation for a particular vote is reasonable using the LLM. We tested our methodology on 52 jokes in a crowd of four AI voters with different humour types: affiliative, self-enhancing, aggressive and self-defeating. Our results show that few-shot prompting leads to better results than zero-shot for the voting question. Personality induction showed that aggressive and self-defeating voters are significantly more inclined to find more jokes funny of a set of aggressive/self-defeating jokes than the affiliative and self-enhancing voters. The Crowd Score follows the same trend as human judges by assigning higher scores to jokes that are also considered funnier by human judges. We believe that our methodology could be applied to other creative domains such as story, poetry, slogans, etc. It could both help the adoption of a flexible and accurate standard approach to compare different work in the CC community under a common metric and by minimizing human participation in assessing creative artefacts, it could accelerate the prototyping of creative artefacts and reduce the cost of hiring human participants to rate creative artefacts.
翻译:本文介绍了《人群评分》,这是用来评估笑话的有趣性的一种新颖方法,它使用大语言模型(LLMs)作为AI法官。我们的方法依靠的是将不同的人物引入LLM,并将AI法官的选票集中到一个分数中,以评分笑话。我们用LM来验证这种审计方法,如果对特定投票的解释合理,则用LLM来核对。我们测试了在四位AI选民群中52个笑话的方法,这四人具有不同的幽默类型:顺从性、自我提升、攻击性和自我败坏。我们的结果显示,少发的提示会比投票问题的零分带来更好的结果。个人评分表明,攻击性和自我败诉选民的选票更倾向于发现一套攻击性/自我贬低的笑话,比起辅助和自我提升选民的笑话。 人群评分与人类法官一样,在人类法官也认为更有趣的笑话上,我们的方法可以适用于其他创造性的领域,例如故事、诗歌、口号、自我败诉选民们的选票。 个人感感感感感感感上,更愿意找到更有趣的笑话,通过共同的创性手法,可以用来评估创新性手法的进度,用来评估创新性方法,从而降低成本,可以帮助评估创新的参与者参与率。