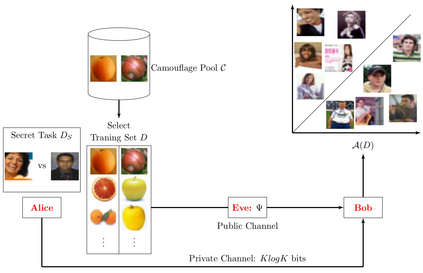
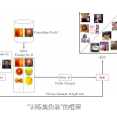
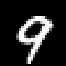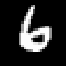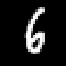We introduce a form of steganography in the domain of machine learning which we call training set camouflage. Imagine Alice has a training set on an illicit machine learning classification task. Alice wants Bob (a machine learning system) to learn the task. However, sending either the training set or the trained model to Bob can raise suspicion if the communication is monitored. Training set camouflage allows Alice to compute a second training set on a completely different -- and seemingly benign -- classification task. By construction, sending the second training set will not raise suspicion. When Bob applies his standard (public) learning algorithm to the second training set, he approximately recovers the classifier on the original task. Training set camouflage is a novel form of steganography in machine learning. We formulate training set camouflage as a combinatorial bilevel optimization problem and propose solvers based on nonlinear programming and local search. Experiments on real classification tasks demonstrate the feasibility of such camouflage.
翻译:我们在机器学习领域引入了一种形式,我们称之为培训套装伪装。想象爱丽丝拥有一套关于非法机器学习分类任务的培训。爱丽丝希望鲍勃(机器学习系统)学习这个任务。然而,如果将培训套件或经过培训的模式发送到鲍勃,如果通信受到监测,可能会引起怀疑。训练套装伪装使爱丽丝能够根据完全不同的 -- -- 似乎无害的 -- -- 分类任务计算第二个培训套件。通过构建,发送第二个培训套件不会引起怀疑。当鲍勃将标准(公共)学习算法应用到第二个培训套件时,他大概会恢复原任务的分类师。培训套装是机器学习中一种新颖的血色学形式。我们把培训套件设计成一个双级组合优化问题,并根据非线性编程和本地搜索提出解决方案。对真实分类任务进行实验表明这种伪装的可行性。