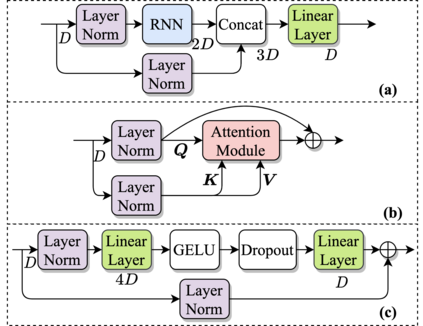
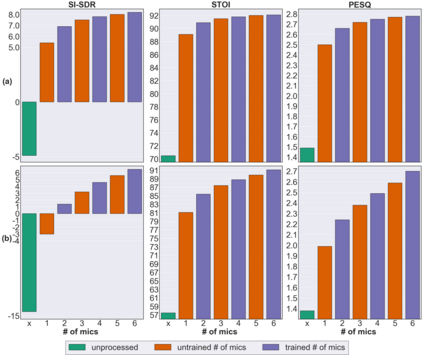
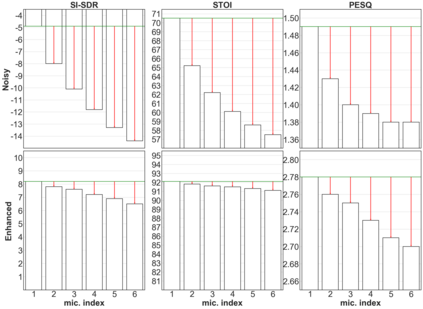
Deep neural networks (DNNs) have been successfully used for multichannel speech enhancement in fixed array geometries. However, challenges remain for ad-hoc arrays with unknown microphone placements. We propose a deep neural network based approach for ad-hoc array processing: Triple-Attentive Dual-Recurrent Network (TADRN). TADRN uses self-attention across channels for learning spatial information and a dual-path attentive recurrent network (ARN) for temporal modeling. Temporal modeling is done independently for all channels by dividing a signal into smaller chunks and using an intra-chunk ARN for local modeling and an inter-chunk ARN for global modeling. Consequently, TADRN uses triple-path attention: inter-channel, intra-chunk, and inter-chunk, and dual-path recurrence: intra-chunk and inter-chunk. Experimental results show excellent performance of TADRN. We demonstrate that TADRN improves speech enhancement by leveraging additional randomly placed microphones, even at locations far from the target source. Additionally, large improvements in objective scores are observed when poorly placed microphones in the scene are complemented with more effective microphone positions, such as those closer to a target source.
翻译:在固定阵列地形中,深海神经网络(DNNs)被成功地用于多通道语音增强。然而,具有未知麦克风定位的特设阵列仍然存在挑战。我们提议了基于深神经网络的特设阵列处理方法:三-加速双流网络(TADRN)。TADRN利用跨渠道的自我关注来学习空间信息,并使用双向关注的经常性网络进行时间建模。对所有频道来说,时间建模是独立进行的,方法是将信号分割成小块,使用中式ARN进行本地建模,并使用中式ARN进行全球建模。因此,TADRN使用三重心心:跨通道、中式双向双向网络(TADRN)和双向重复(TADRN)的实验结果显示TADRN的出色表现。我们证明,TADRN通过利用更多随机安装的麦克风来改进语音,即使是在远离目标源的地点,也使用内部安装的ARN,而内部的ARN也使用一个内部建式ARN。此外,在目标定位上,更精确的移动式定位的位置是更接近目标定位。