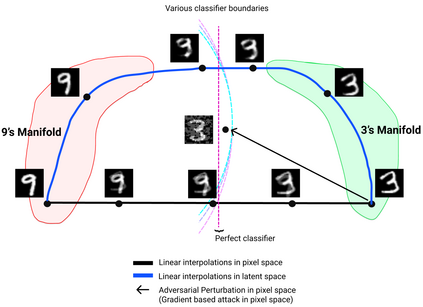
Traditional adversarial attacks rely upon the perturbations generated by gradients from the network which are generally safeguarded by gradient guided search to provide an adversarial counterpart to the network. In this paper, we propose a novel mechanism of generating adversarial examples where the actual image is not corrupted rather its latent space representation is utilized to tamper with the inherent structure of the image while maintaining the perceptual quality intact and to act as legitimate data samples. As opposed to gradient-based attacks, the latent space poisoning exploits the inclination of classifiers to model the independent and identical distribution of the training dataset and tricks it by producing out of distribution samples. We train a disentangled variational autoencoder (beta-VAE) to model the data in latent space and then we add noise perturbations using a class-conditioned distribution function to the latent space under the constraint that it is misclassified to the target label. Our empirical results on MNIST, SVHN, and CelebA dataset validate that the generated adversarial examples can easily fool robust l_0, l_2, l_inf norm classifiers designed using provably robust defense mechanisms.
翻译:传统的对抗性攻击依赖于网络梯度造成的扰动, 通常通过梯度引导搜索来保护这些梯度, 以提供网络的对抗性对应方。 在本文中, 我们提出一个新的机制, 产生一个对抗性实例, 即实际图像没有腐蚀, 而是其潜在的空间代表面被用来改变图像的内在结构, 同时保持感知质量完整, 并充当合法的数据样本。 相对于基于梯度的攻击, 潜伏的空间中毒利用分类人员的意愿来模拟培训数据集的独立和相同的分布, 并通过制作分发样本来进行技巧。 我们训练一个分解的自动变异编码器(beta- VaE)来模拟潜层空间的数据, 然后利用一个等级固定的分布功能, 来改变图像的内在空间的内在结构。 我们关于MNIST、 SVHN 和 CeebebA 数据集的经验结果证实, 生成的对抗性实例很容易愚弄可靠的I_0、 l_ 2、 l_ inf 规范分类器, 设计为使用可辨称稳健的防御机制设计。