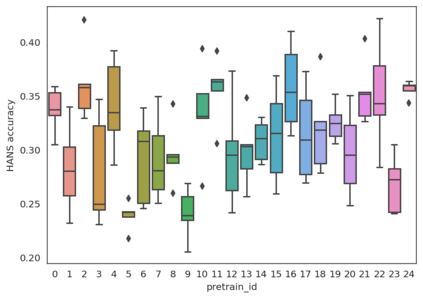
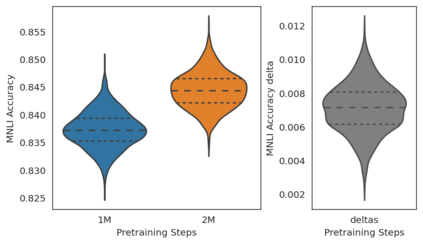
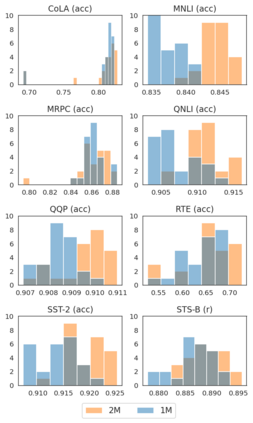
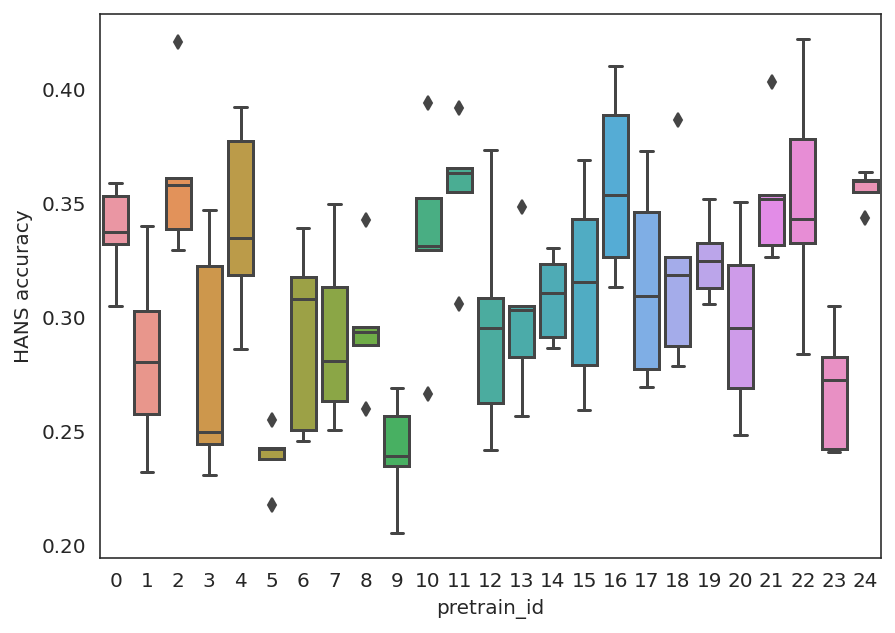
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.
翻译:虽然得出的结论适用于文物(即该模型的具体实例),但并非始终清楚它们是否坚持更一般的程序(包括模型结构、培训数据、初始化计划和损失功能)。最近的工作表明,重新运行的预科培训可导致关于业绩的完全不同的结论,表明需要进行其他评估,才能就程序作出有原则的声明。为了解决这一问题,我们引入了多边界专家小组:一套25个多边界专家小组基地检查站,其训练的高度参数与原模型相似,但在随机初始化和数据打乱方面却有所不同。目的是使研究人员能够就培训前程序得出稳健和有统计依据的结论。全面释放包括25个经过充分训练的检查站,以及统计指南和一个守则图书馆,以落实我们建议的假设测试方法。最后,对于其中5个模型,我们发布了一套28个中间检查站,以支持学习动态研究。