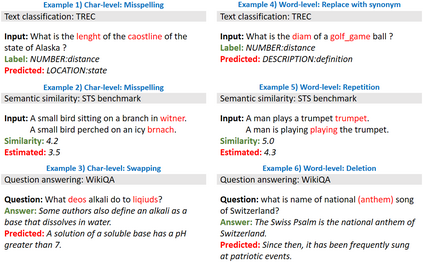
High-performance neural language models have obtained state-of-the-art results on a wide range of Natural Language Processing (NLP) tasks. However, results for common benchmark datasets often do not reflect model reliability and robustness when applied to noisy, real-world data. In this study, we design and implement various types of character-level and word-level perturbation methods to simulate realistic scenarios in which input texts may be slightly noisy or different from the data distribution on which NLP systems were trained. Conducting comprehensive experiments on different NLP tasks, we investigate the ability of high-performance language models such as BERT, XLNet, RoBERTa, and ELMo in handling different types of input perturbations. The results suggest that language models are sensitive to input perturbations and their performance can decrease even when small changes are introduced. We highlight that models need to be further improved and that current benchmarks are not reflecting model robustness well. We argue that evaluations on perturbed inputs should routinely complement widely-used benchmarks in order to yield a more realistic understanding of NLP systems robustness.
翻译:高性能神经语言模型在一系列广泛的自然语言处理(NLP)任务中取得了最先进的结果,然而,通用基准数据集的结果往往不能反映模型的可靠性和稳健性,而应用于吵闹的、真实世界的数据。在本研究中,我们设计和执行了各种类型的品格水平和字级扰动方法,以模拟现实情景,在这些情景中,输入文本可能略为吵动或与NLP系统所培训的数据分布不同。对不同的自然语言处理任务进行全面试验,我们调查高性能语言模型(如BERT、XLNet、ROBERTA和ELMO)在处理不同类型输入扰动时的能力。结果显示,语言模型对输入扰动很敏感,即使在引入小的改动时,其性能也会降低。我们强调,模型需要进一步改进,目前的基准并不反映模型稳健。我们主张,关于渗透性投入的评价应经常补充广泛使用的基准,以便更现实地了解NLP系统是否稳健。