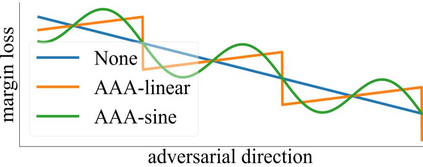
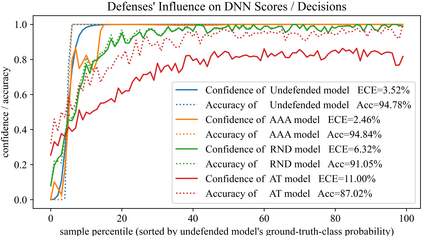
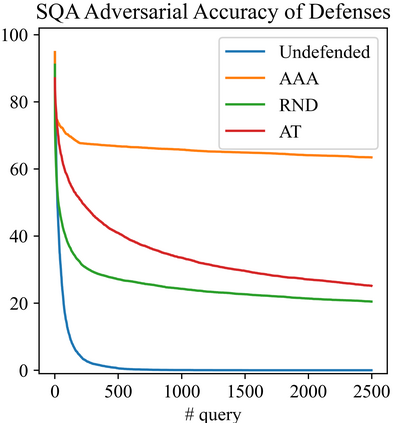
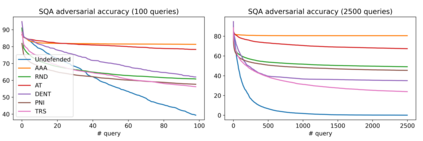
The score-based query attacks (SQAs) pose practical threats to deep neural networks by crafting adversarial perturbations within dozens of queries, only using the model's output scores. Nonetheless, we note that if the loss trend of the outputs is slightly perturbed, SQAs could be easily misled and thereby become much less effective. Following this idea, we propose a novel defense, namely Adversarial Attack on Attackers (AAA), to confound SQAs towards incorrect attack directions by slightly modifying the output logits. In this way, (1) SQAs are prevented regardless of the model's worst-case robustness; (2) the original model predictions are hardly changed, i.e., no degradation on clean accuracy; (3) the calibration of confidence scores can be improved simultaneously. Extensive experiments are provided to verify the above advantages. For example, by setting $\ell_\infty=8/255$ on CIFAR-10, our proposed AAA helps WideResNet-28 secure 80.59% accuracy under Square attack (2500 queries), while the best prior defense (i.e., adversarial training) only attains 67.44%. Since AAA attacks SQA's general greedy strategy, such advantages of AAA over 8 defenses can be consistently observed on 8 CIFAR-10/ImageNet models under 6 SQAs, using different attack targets, bounds, norms, losses, and strategies. Moreover, AAA calibrates better without hurting the accuracy. Our code is available at https://github.com/Sizhe-Chen/AAA.
翻译:基于分数的查询攻击(SQAs)对深神经网络构成实际威胁,在几十个查询中制造对抗性干扰,只使用模型输出分数。然而,我们注意到,如果产出的损失趋势略为扰动,SQA很容易被误导,从而变得低效得多。根据这个想法,我们提议一种新的辩护,即对攻击者进行反向攻击(AAAA),通过略微修改输出日志,使SQA对错误攻击方向产生混淆。这样,(1) SQA被阻止,而不管模型最坏的精确度如何;(2) 最初的模型预测几乎没有改变,即没有降低清洁的准确性;(3) 信任分数的校准可以同时改进。我们提供了广泛的实验来核实上述优势。例如,在CFAR-10上设置了 $@ell_infty=8/255美元,我们提议的AAAAA 代码有助于广域网-28安全性精确度2500查询,而前最好的防御(i.e.A-ralalalalalal a trainal ress a destruestrational a destrational a destruestrubal a destrational destrational destrational destrational destrational destrational as) as A.