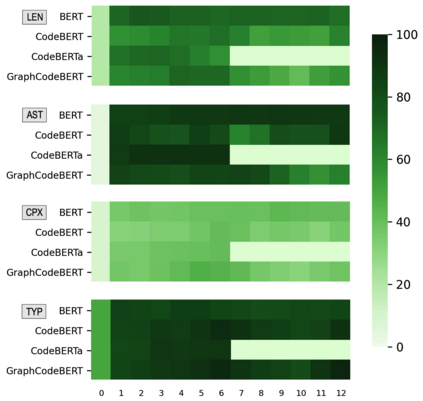
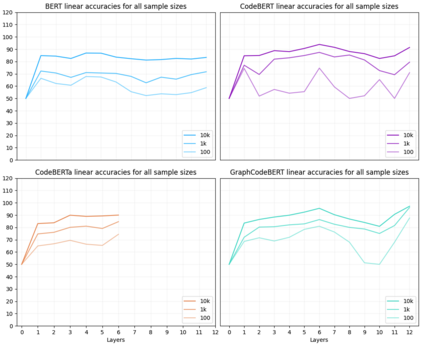
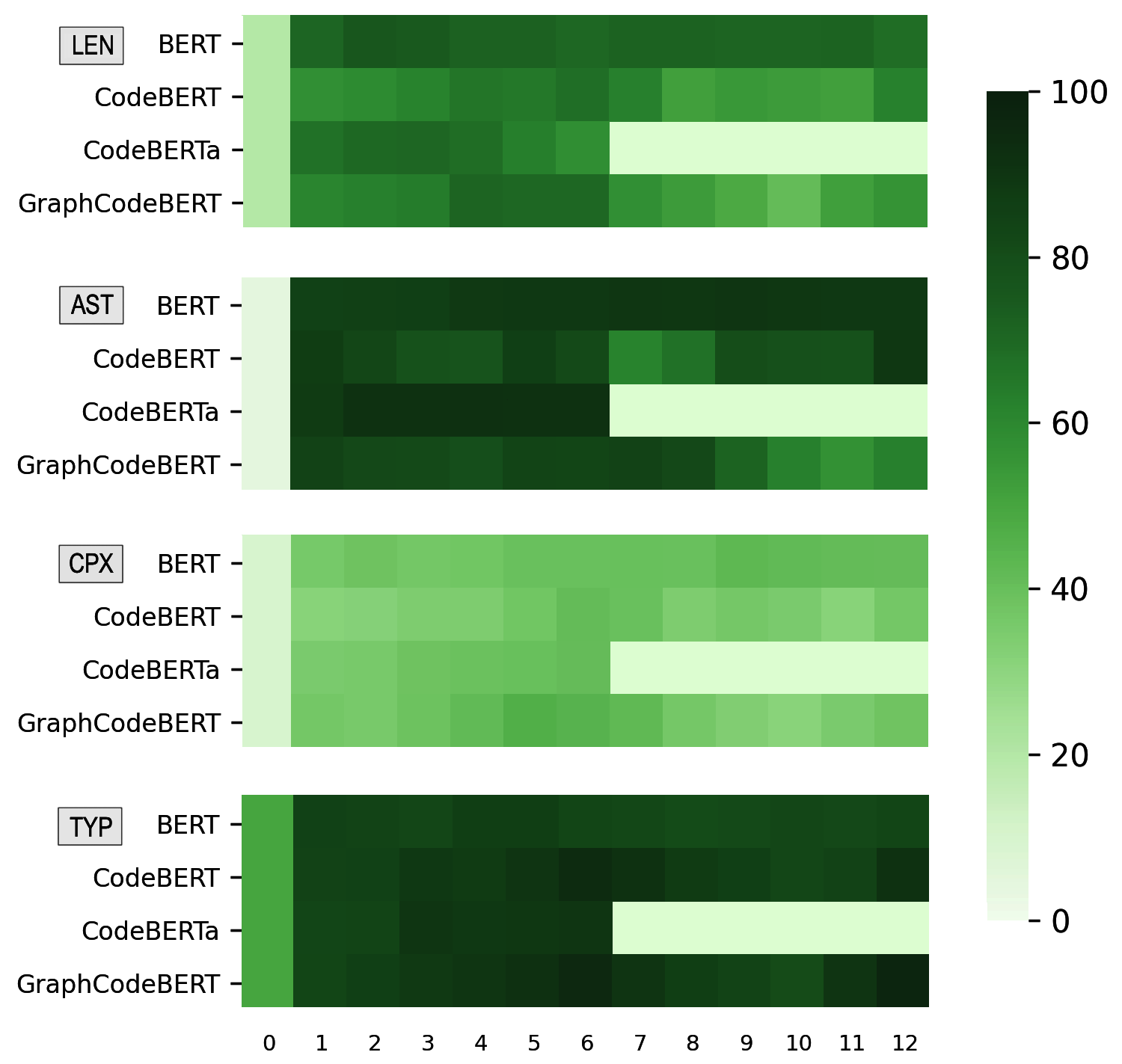
Pre-trained models of code built on the transformer architecture have performed well on software engineering (SE) tasks such as predictive code generation, code summarization, among others. However, whether the vector representations from these pre-trained models comprehensively encode characteristics of source code well enough to be applicable to a broad spectrum of downstream tasks remains an open question. One way to investigate this is with diagnostic tasks called probes. In this paper, we construct four probing tasks (probing for surface-level, syntactic, structural, and semantic information) for pre-trained code models. We show how probes can be used to identify whether models are deficient in (understanding) certain code properties, characterize different model layers, and get insight into the model sample-efficiency. We probe four models that vary in their expected knowledge of code properties: BERT (pre-trained on English), CodeBERT and CodeBERTa (pre-trained on source code, and natural language documentation), and GraphCodeBERT (pre-trained on source code with dataflow). While GraphCodeBERT performs more consistently overall, we find that BERT performs surprisingly well on some code tasks, which calls for further investigation.
翻译:在变压器结构上建立的经过预先培训的代码模型在软件工程任务方面表现良好,例如预测代码生成、代码总和等。然而,这些经过预先培训的模型的矢量表示是否全面编码源代码的特性,足以适用于广泛的下游任务,仍然是一个未决问题。调查的方法之一是进行诊断性任务,称为探测器。在本文件中,我们为预先培训的代码模型设计了四种探测性任务(地表、合成、结构和语义信息测试)。我们展示了如何使用探测器来确定模型是否在某些代码属性(理解)方面有缺陷,不同模型层的特点,并深入了解示范效率。我们发现了四种模型,这些模型的预期特性知识各不相同:BERT(英语预先培训)、DCBERT和DCBERTA(源代码和自然语言文件预培训),以及SapCodeBERT(源代码预培训,数据流)。我们发现,尽管GIDODERT在总体上进行了更加一致的操作,但我们发现,BERT在一些代码任务上表现得惊人,这要求进一步调查。