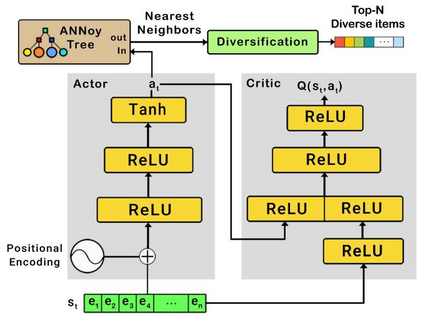
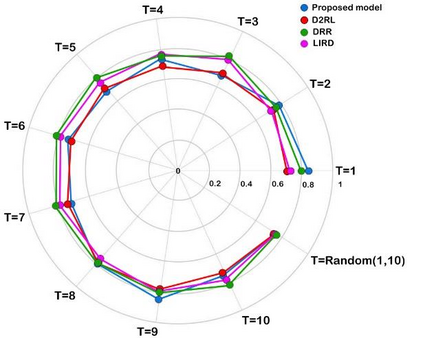
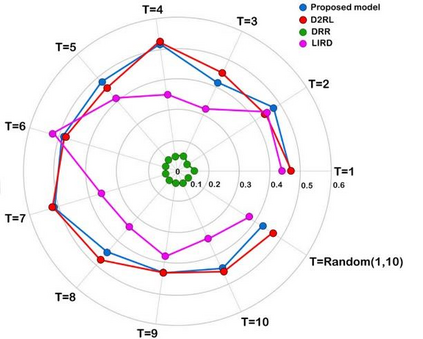
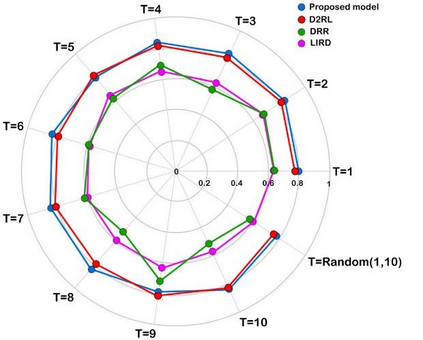
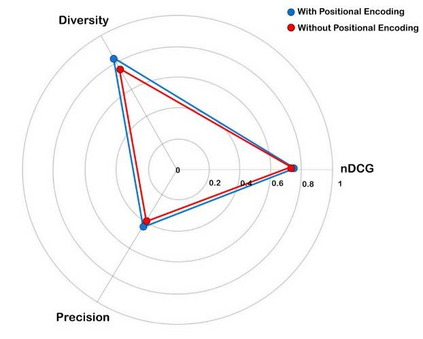
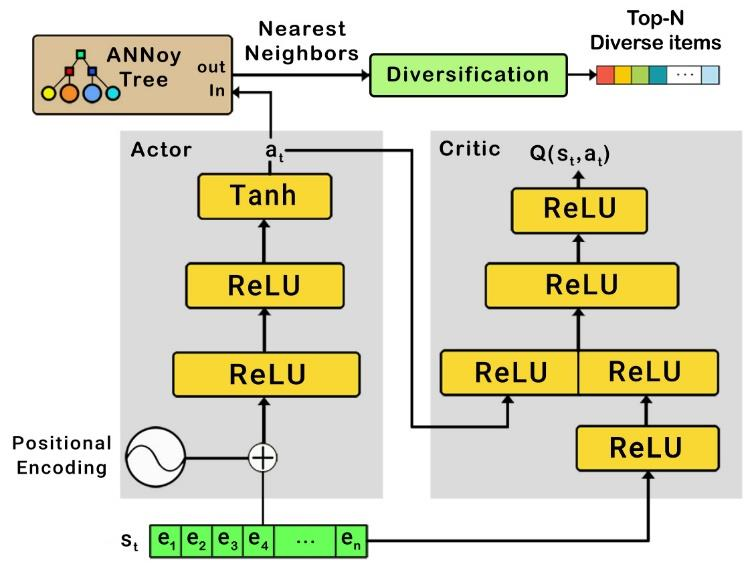
Recently, interactive recommendation systems based on reinforcement learning have been attended by researchers due to the consider recommendation procedure as a dynamic process and update the recommendation model based on immediate user feedback, which is neglected in traditional methods. The existing works have two significant drawbacks. Firstly, inefficient ranking function to produce the Top-N recommendation list. Secondly, focusing on recommendation accuracy and inattention to other evaluation metrics such as diversity. This paper proposes a deep reinforcement learning based recommendation system by utilizing Actor-Critic architecture to model dynamic users' interaction with the recommender agent and maximize the expected long-term reward. Furthermore, we propose utilizing Spotify's ANNoy algorithm to find the most similar items to generated action by actor-network. After that, the Total Diversity Effect Ranking algorithm is used to generate the recommendations concerning relevancy and diversity. Moreover, we apply positional encoding to compute representations of the user's interaction sequence without using sequence-aligned recurrent neural networks. Extensive experiments on the MovieLens dataset demonstrate that our proposed model is able to generate a diverse while relevance recommendation list based on the user's preferences.
翻译:最近,研究人员参加了基于强化学习的互动式建议系统,原因是将建议程序视为动态程序,并更新基于即时用户反馈的建议模式,而传统方法忽视了这种程序。现有工作有两个重大缺点。首先,低效排名功能生成“顶层-N”建议列表。第二,侧重于建议准确性和对多样性等其他评价指标的注意。本文件提议采用基于“行动-批评”的建议系统,利用“行动-批评”架构来模拟用户与推荐人的互动,并最大限度地发挥预期的长期奖励。此外,我们提议利用“Spotify”的“ANNoy”算法来寻找最类似的项目,以形成行为者网络行动。之后,“全面多样性效应排序算法”被用来生成关于相关性和多样性的建议。此外,我们采用定位编码来计算用户互动序列的表达方式,而不使用顺序对齐的重复神经网络。在MeopleLens数据集上进行的广泛实验表明,我们提议的模型能够产生多样化,同时根据用户的偏好度提供相关建议列表。