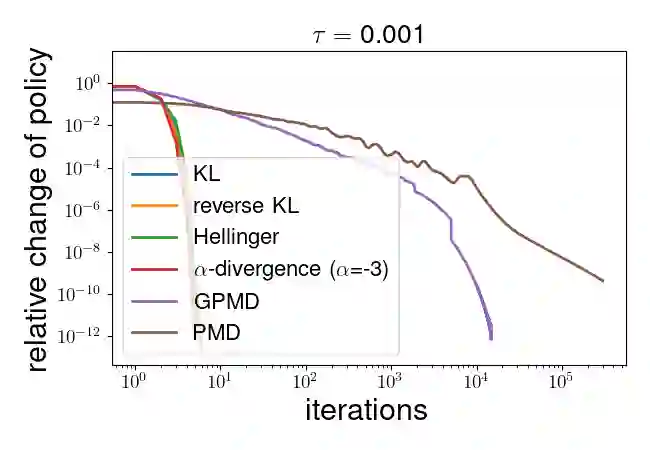
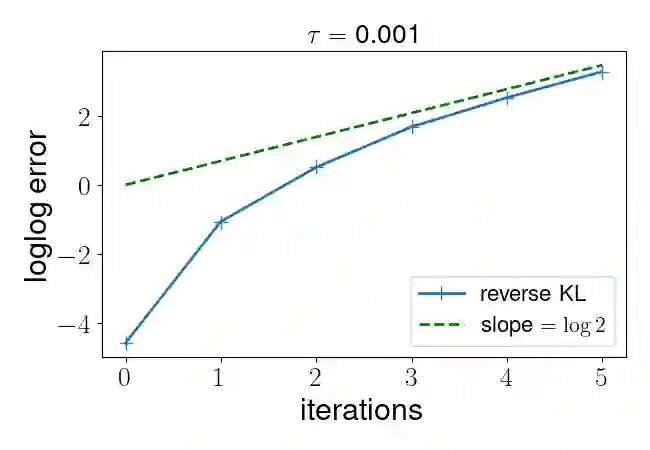
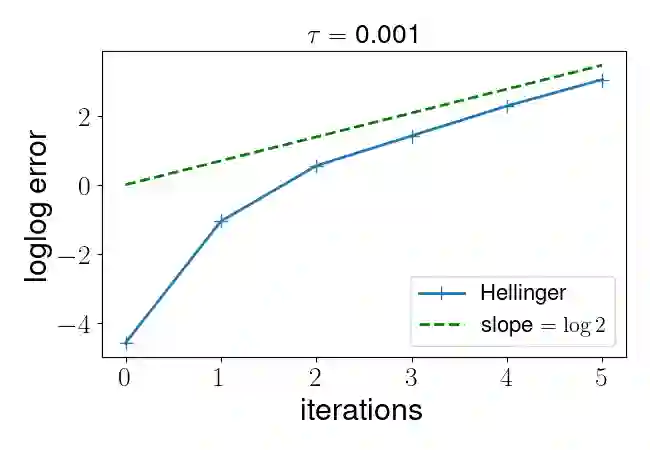
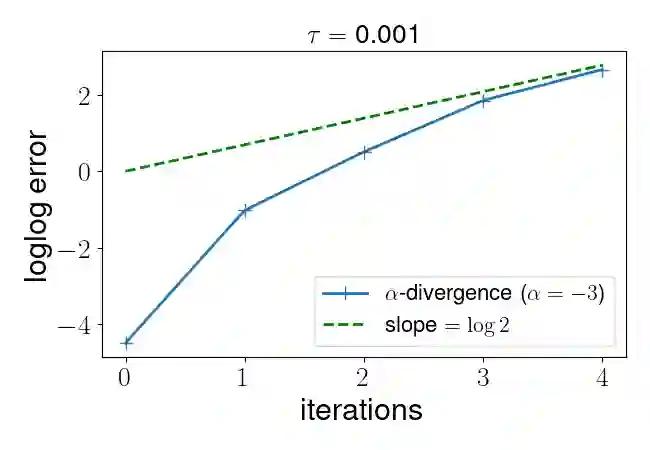
Policy gradient algorithms have been widely applied to reinforcement learning (RL) problems in recent years. Regularization with various entropy functions is often used to encourage exploration and improve stability. In this paper, we propose a quasi-Newton method for the policy gradient algorithm with entropy regularization. In the case of Shannon entropy, the resulting algorithm reproduces the natural policy gradient (NPG) algorithm. For other entropy functions, this method results in brand new policy gradient algorithms. We provide a simple proof that all these algorithms enjoy the Newton-type quadratic convergence near the optimal policy. Using synthetic and industrial-scale examples, we demonstrate that the proposed quasi-Newton method typically converges in single-digit iterations, often orders of magnitude faster than other state-of-the-art algorithms.
翻译:近年来,政策梯度算法被广泛应用于强化学习(RL)问题。 使用各种英特罗比函数的正规化常常被用来鼓励探索和增强稳定性。 在本文中,我们提出了使用英特罗比正规化的政策梯度算法的准牛顿方法。 在香农英特罗比的情况下,由此产生的演算法复制了自然政策梯度算法。对于其他英特罗比函数,这种方法产生品牌的新政策梯度算法。我们提供了一个简单的证据,证明所有这些算法都享有牛顿型四边形接近最佳政策的趋同。我们用合成和工业规模的例子来证明,拟议的准牛顿方法通常会以单位数字迭代法相融合,通常比其他最先进的算法速度更快。