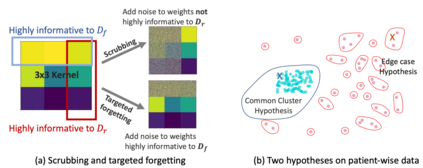
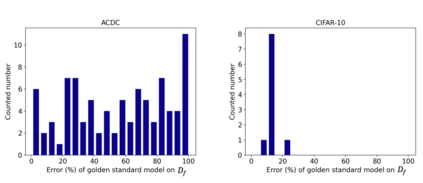
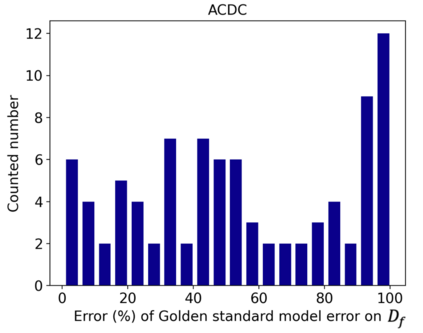
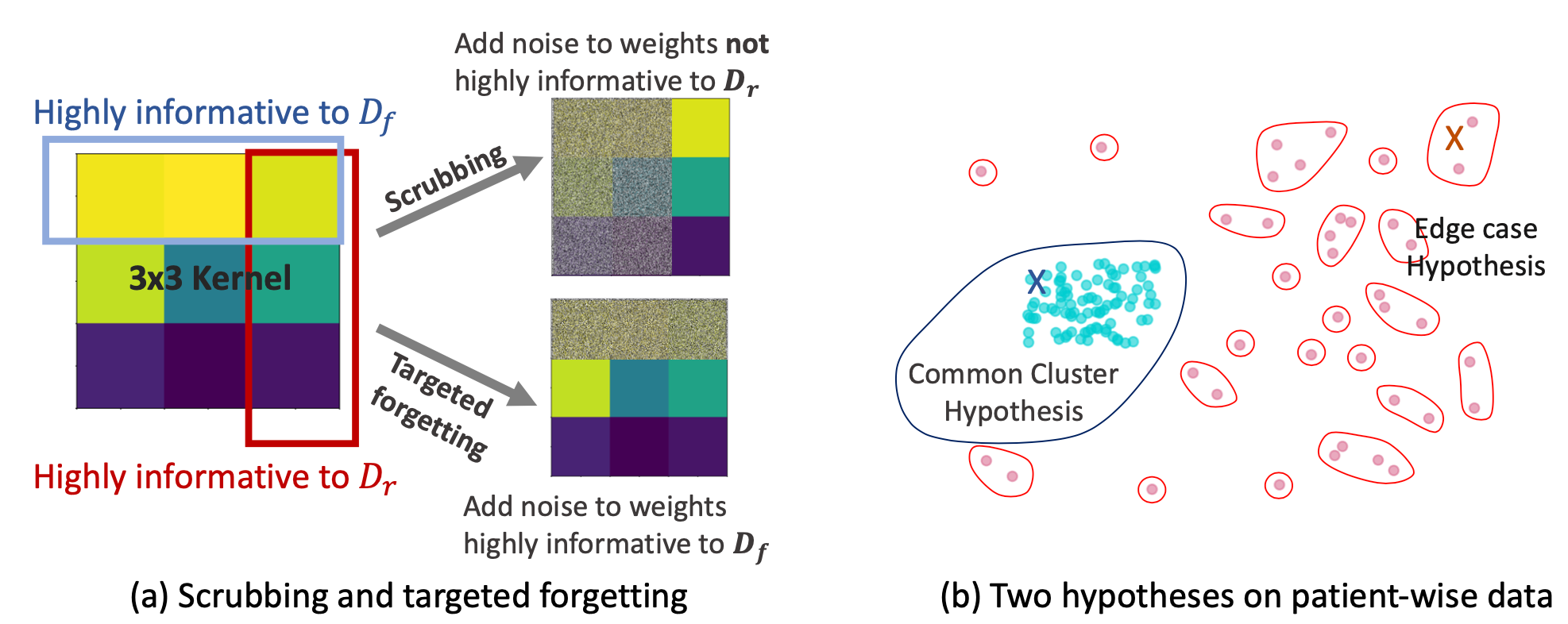
Rights provisioned within data protection regulations, permit patients to request that knowledge about their information be eliminated by data holders. With the advent of AI learned on data, one can imagine that such rights can extent to requests for forgetting knowledge of patient's data within AI models. However, forgetting patients' imaging data from AI models, is still an under-explored problem. In this paper, we study the influence of patient data on model performance and formulate two hypotheses for a patient's data: either they are common and similar to other patients or form edge cases, i.e. unique and rare cases. We show that it is not possible to easily forget patient data. We propose a targeted forgetting approach to perform patient-wise forgetting. Extensive experiments on the benchmark Automated Cardiac Diagnosis Challenge dataset showcase the improved performance of the proposed targeted forgetting approach as opposed to a state-of-the-art method.
翻译:在数据保护条例中规定的权利,允许病人要求数据持有者消除有关其信息的知识。随着AI数据知识的出现,人们可以想象到,这种权利可以扩大到在AI模型中要求忘记病人数据知识的要求。然而,忘记AI模型中的病人成像数据,仍然是一个未得到充分探讨的问题。在本文中,我们研究了病人数据对模型性能的影响,并为病人数据制定了两种假设:要么是常见的,与其他病人相似,要么是形成边缘病例,即独特和罕见病例。我们表明不可能轻易忘记病人数据。我们建议了一种有针对性的遗忘方法,以便从病人的角度进行遗忘。关于自动心肺病诊断的挑战数据集的基准的广泛实验展示了拟议的目标性遗忘方法相对于最先进的方法的改进性能。