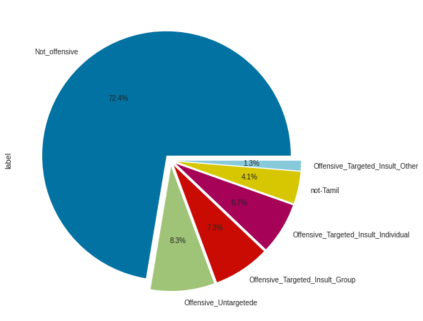
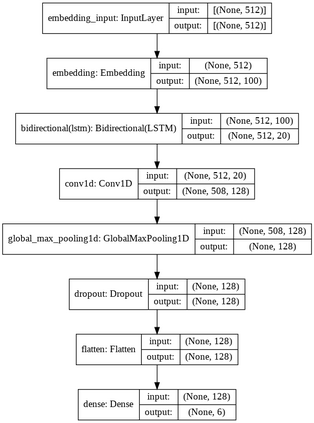
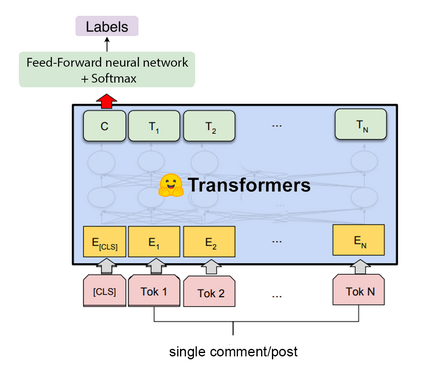
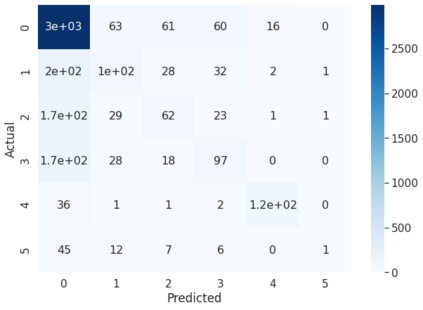
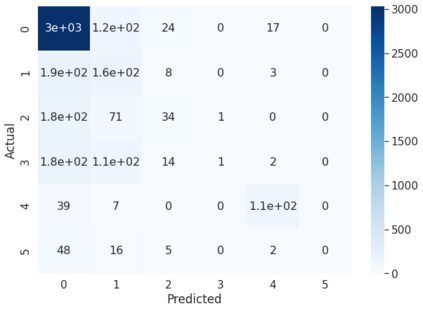
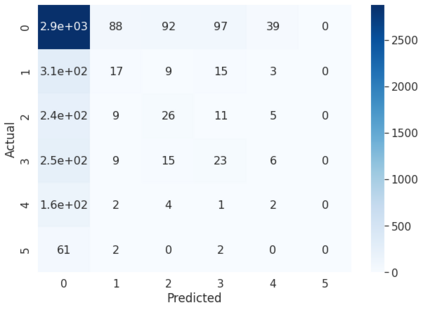
Offensive Language detection in social media platforms has been an active field of research over the past years. In non-native English spoken countries, social media users mostly use a code-mixed form of text in their posts/comments. This poses several challenges in the offensive content identification tasks, and considering the low resources available for Tamil, the task becomes much harder. The current study presents extensive experiments using multiple deep learning, and transfer learning models to detect offensive content on YouTube. We propose a novel and flexible approach of selective translation and transliteration techniques to reap better results from fine-tuning and ensembling multilingual transformer networks like BERT, Distil- BERT, and XLM-RoBERTa. The experimental results showed that ULMFiT is the best model for this task. The best performing models were ULMFiT and mBERTBiLSTM for this Tamil code-mix dataset instead of more popular transfer learning models such as Distil- BERT and XLM-RoBERTa and hybrid deep learning models. The proposed model ULMFiT and mBERTBiLSTM yielded good results and are promising for effective offensive speech identification in low-resourced languages.
翻译:过去几年来,在社交媒体平台中,攻击性语言探测一直是积极研究的领域。在非本地英语语言国家,社交媒体用户大多在文章/评论中使用一种编码混合的文本形式。这给攻击性内容识别任务带来了若干挑战,而且考虑到泰米尔人可利用的资源很少,这项任务就更加困难了。本研究报告介绍了使用多种深层学习的广泛实验,并传输学习模型,以探测YouTube上的冒犯性内容。我们提出了一种新颖和灵活的选择性翻译和转写技术方法,以便从微调和融合多语种变异器网络(如BERT、Distil-BERT和XLLM-ROBERTA)中取得更好的结果。实验结果表明,ULMFiT是这项任务的最佳模式。最好的模式是泰米尔语代码混合数据集的ULMFi和MBERTBLISTM, 而不是诸如DIT-BERT和XLM-ROBERTA和混合深层学习模型等更受欢迎的转移学习模型。拟议的ULMiT和MTBERTLSTM模型取得了良好的结果,并且有望在低资源语言中有效地识别攻击性言。