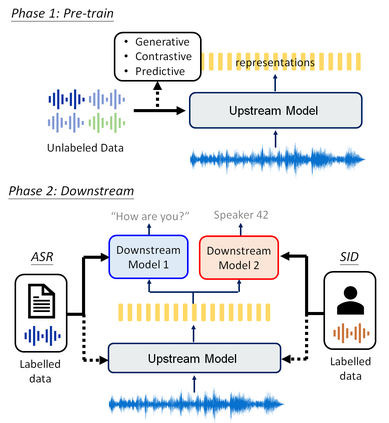
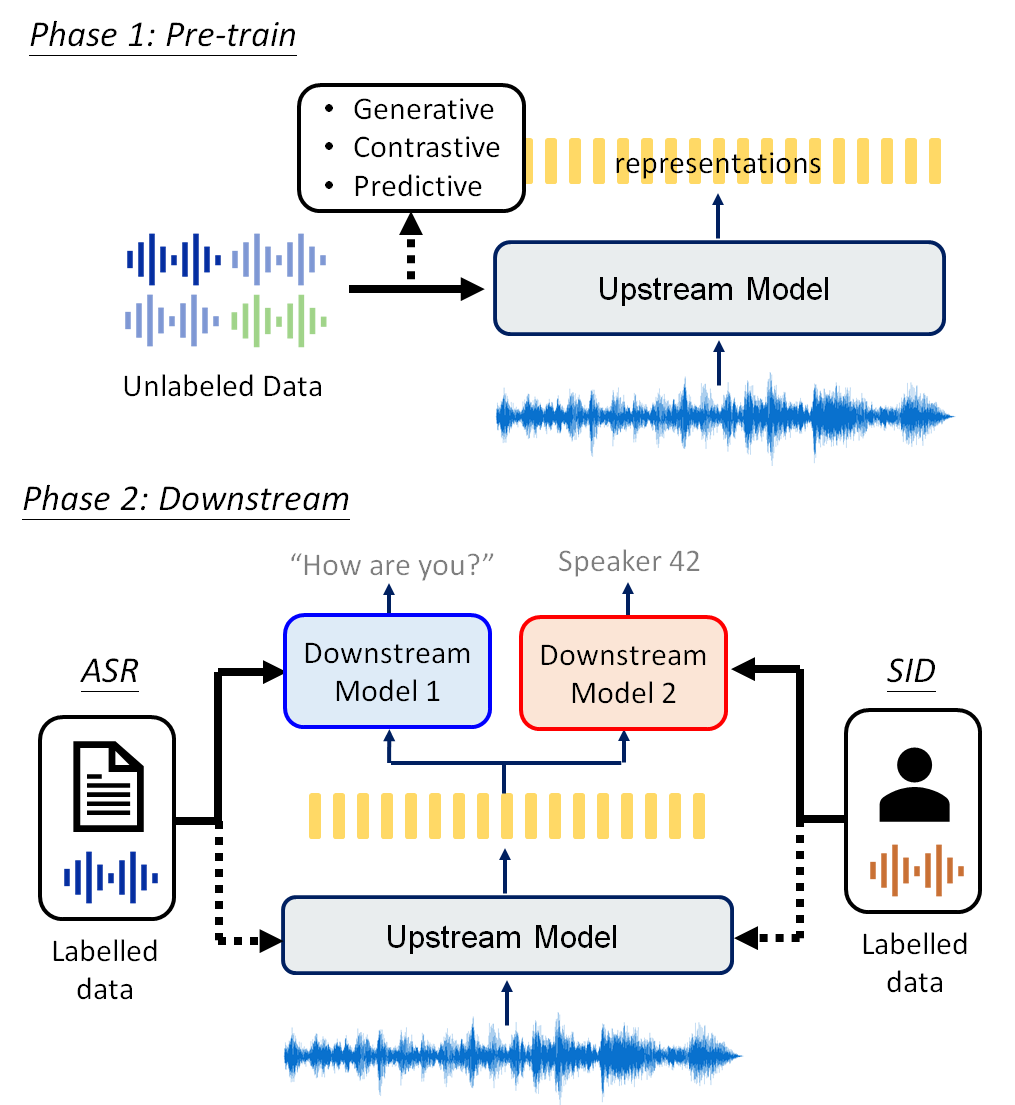
Although supervised deep learning has revolutionized speech and audio processing, it has necessitated the building of specialist models for individual tasks and application scenarios. It is likewise difficult to apply this to dialects and languages for which only limited labeled data is available. Self-supervised representation learning methods promise a single universal model that would benefit a wide variety of tasks and domains. Such methods have shown success in natural language processing and computer vision domains, achieving new levels of performance while reducing the number of labels required for many downstream scenarios. Speech representation learning is experiencing similar progress in three main categories: generative, contrastive, and predictive methods. Other approaches rely on multi-modal data for pre-training, mixing text or visual data streams with speech. Although self-supervised speech representation is still a nascent research area, it is closely related to acoustic word embedding and learning with zero lexical resources, both of which have seen active research for many years. This review presents approaches for self-supervised speech representation learning and their connection to other research areas. Since many current methods focus solely on automatic speech recognition as a downstream task, we review recent efforts on benchmarking learned representations to extend the application beyond speech recognition.
翻译:虽然经过监督的深层学习使语音和音频处理革命了,但有必要为个别任务和应用设想方案建立专家模型,同样难以将这一模型应用于只有有限标签数据的方言和语言;自我监督的代表学习方法承诺采用单一的普遍模式,有利于各种各样的任务和领域;这些方法在自然语言处理和计算机视觉领域取得了成功,实现了新的业绩水平,同时减少了许多下游情景所需的标签数量;语音代表学习在三个主要类别(基因化、对比和预测方法)上也取得了类似进展;其他方法依赖多种模式数据,用于培训前、文本或视觉数据流与语音的混合;虽然自我监督的语音代表仍然是新生研究领域,但与用零词汇资源嵌入和学习的声音词密切相关,两者多年来都进行了积极研究;本审查提出了自我监督的语音代表学习方法及其与其他研究领域的联系。由于许多现行方法仅将自动语音识别作为下游任务,因此我们审查最近关于将学习的表述基准工作的努力,将应用扩大到语音识别之外。