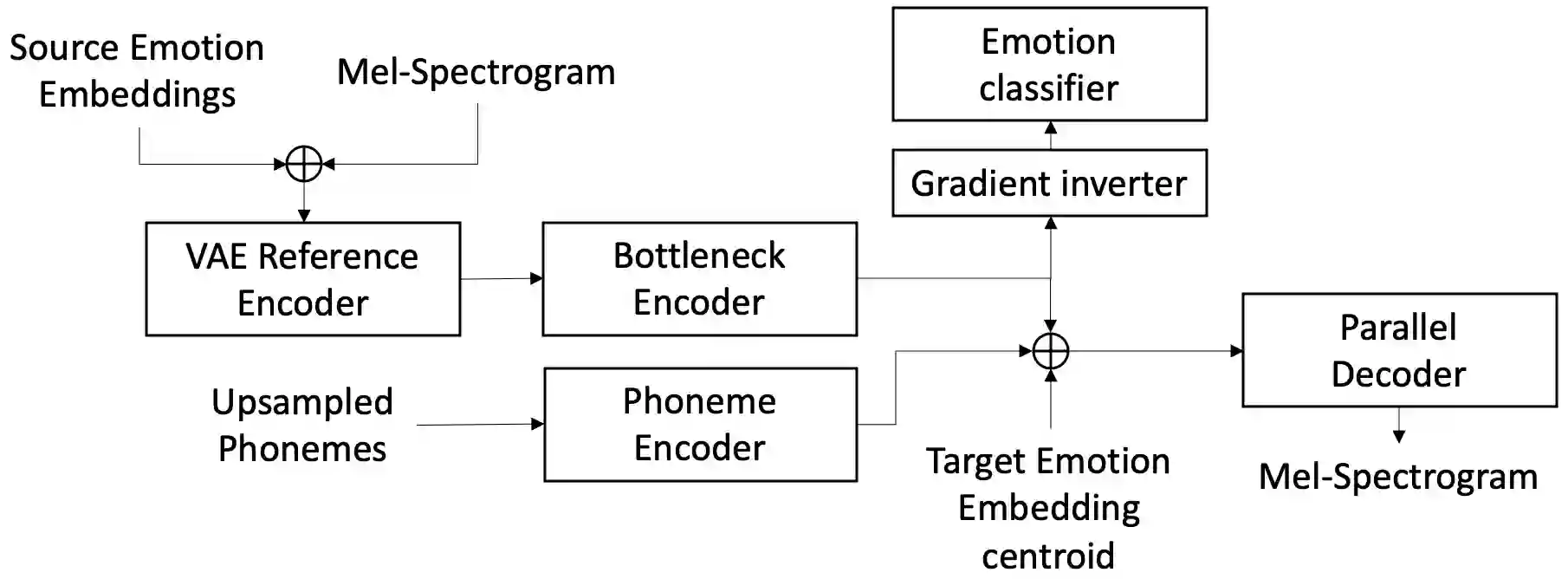
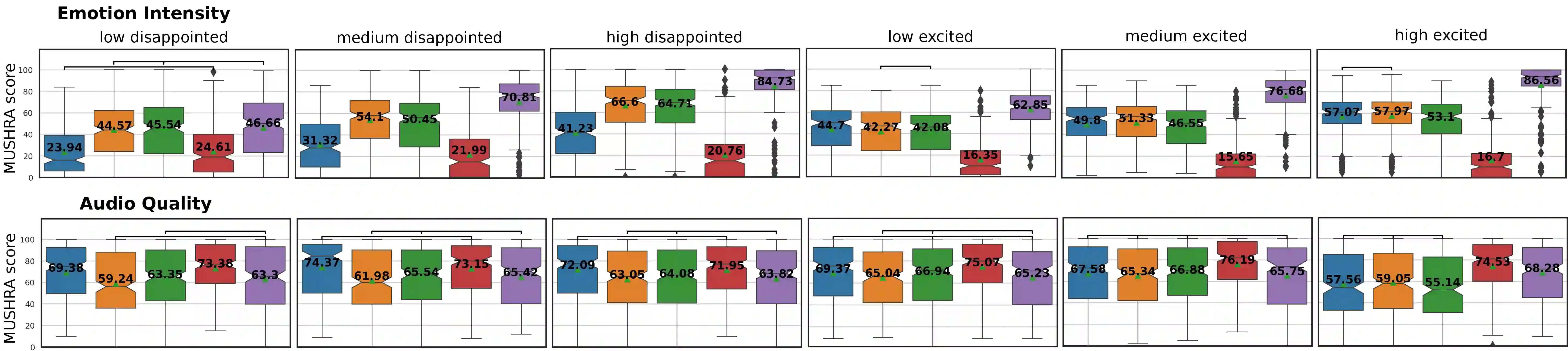
Emotional voice conversion models adapt the emotion in speech without changing the speaker identity or linguistic content. They are less data hungry than text-to-speech models and allow to generate large amounts of emotional data for downstream tasks. In this work we propose EmoCat, a language-agnostic emotional voice conversion model. It achieves high-quality emotion conversion in German with less than 45 minutes of German emotional recordings by exploiting large amounts of emotional data in US English. EmoCat is an encoder-decoder model based on CopyCat, a voice conversion system which transfers prosody. We use adversarial training to remove emotion leakage from the encoder to the decoder. The adversarial training is improved by a novel contribution to gradient reversal to truly reverse gradients. This allows to remove only the leaking information and to converge to better optima with higher conversion performance. Evaluations show that Emocat can convert to different emotions but misses on emotion intensity compared to the recordings, especially for very expressive emotions. EmoCat is able to achieve audio quality on par with the recordings for five out of six tested emotion intensities.
翻译:情感声音转换模型在不改变语言身份或语言内容的情况下适应言语中的情感。 它们比文本到语音模型更缺乏数据, 并且能够为下游任务生成大量情感数据 。 在此工作中, 我们提议 EmoCat, 这是一种语言不可知的情感声音转换模型 。 它通过利用大量美国英语情感数据, 实现了德国语情感转换质量不小于45分钟的德国语情感转换 。 EmoCat 是一种基于复制器( CopyCat ) 的编码解密模型。 我们使用对抗性培训将情感从编码器中渗漏到解密器中。 我们使用对抗性培训将情感泄漏到解密器中。 对抗性培训通过对梯度转换到真正反向梯度的新贡献而得到改进 。 这只能消除泄漏的信息, 并且通过更高的转换性能而更佳的调调。 评估显示, Emocat 可以转换成不同的情感, 但与录音相比, 特别是非常直观的情绪变异。 EmoCat 能够实现方的音质量, 5个测试的录音记录。