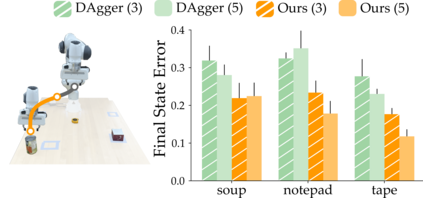
Wheelchair-mounted robotic arms (and other assistive robots) should help their users perform everyday tasks. One way robots can provide this assistance is shared autonomy. Within shared autonomy, both the human and robot maintain control over the robot's motion: as the robot becomes confident it understands what the human wants, it increasingly intervenes to automate the task. But how does the robot know what tasks the human may want to perform in the first place? Today's shared autonomy approaches often rely on prior knowledge: for example, the robot must know the set of possible human goals a priori. In the long-term, however, this prior knowledge will inevitably break down -- sooner or later the human will reach for a goal that the robot did not expect. In this paper we propose a learning approach to shared autonomy that takes advantage of repeated interactions. Learning to assist humans would be impossible if they performed completely different tasks at every interaction: but our insight is that users living with physical disabilities repeat important tasks on a daily basis (e.g., opening the fridge, making coffee, and having dinner). We introduce an algorithm that exploits these repeated interactions to recognize the human's task, replicate similar demonstrations, and return control when unsure. As the human repeatedly works with this robot, our approach continually learns to assist tasks that were never specified beforehand: these tasks include both discrete goals (e.g., reaching a cup) and continuous skills (e.g., opening a drawer). Across simulations and an in-person user study, we demonstrate that robots leveraging our approach match existing shared autonomy methods for known goals, and outperform imitation learning baselines on new tasks. See videos here: https://youtu.be/NazeLVbQ2og
翻译:轮椅上架起的机器人臂(和其他辅助机器人)应该帮助其用户完成日常任务。机器人可以提供这种协助的方式之一是共享自主。在共享自主性的范围内,人类和机器人都可以在共享自主性的范围内对机器人的运动保持控制:随着机器人变得有信心,它可以理解人类想要的东西,它会越来越多地干预任务自动化。但是机器人如何知道人类可能想要执行什么任务呢?今天的共享自主性方法通常取决于先前的知识:例如,机器人必须先先行地了解一套可能的人类自主性。然而,从长远来看,这种先前的知识将不可避免地破碎 -- -- 迟早人类会达到机器人无法预料的目标。在这个文件中,我们提出一个共享自主性的学习方法,利用反复的互动。如果人类每次互动都执行完全不同的任务,那么学习帮助人类是不可能做到的。但是我们的见解是,身体残疾的用户每天重复重要的任务(例如,打开户头,打开户头,煮咖啡,吃晚宴)。我们引入了一种利用这些反复互动性的算法来认识用户的任务,不断学习机器人的任务,不断复制的演示任务。这些任务包括:不断学习的机器人任务,不断学习的技巧。