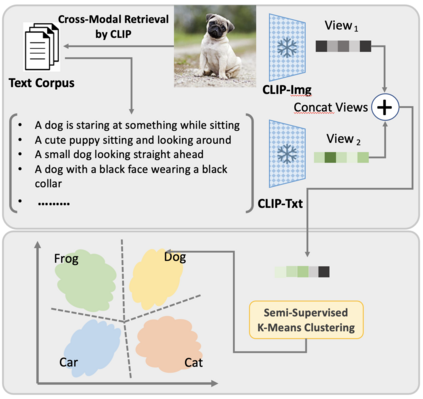
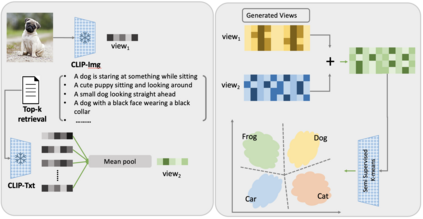
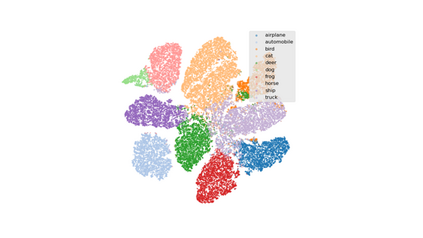
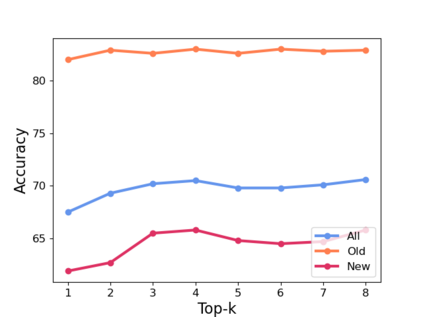
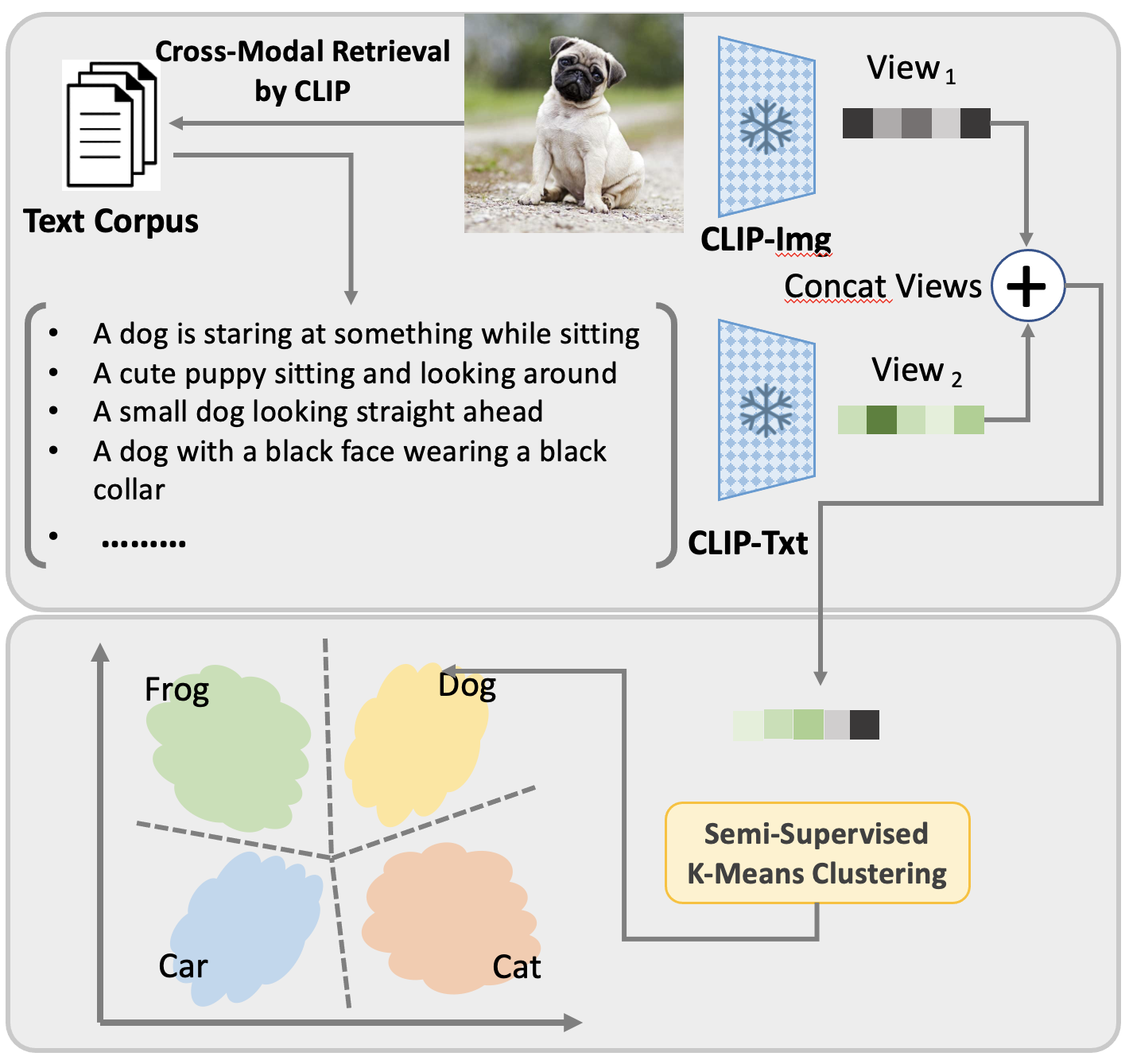
Generalized Category Discovery (GCD) requires a model to both classify known categories and cluster unknown categories in unlabeled data. Prior methods leveraged self-supervised pre-training combined with supervised fine-tuning on the labeled data, followed by simple clustering methods. In this paper, we posit that such methods are still prone to poor performance on out-of-distribution categories, and do not leverage a key ingredient: Semantic relationships between object categories. We therefore propose to leverage multi-modal (vision and language) models, in two complementary ways. First, we establish a strong baseline by replacing uni-modal features with CLIP, inspired by its zero-shot performance. Second, we propose a novel retrieval-based mechanism that leverages CLIP's aligned vision-language representations by mining text descriptions from a text corpus for the labeled and unlabeled set. We specifically use the alignment between CLIP's visual encoding of the image and textual encoding of the corpus to retrieve top-k relevant pieces of text and incorporate their embeddings to perform joint image+text semi-supervised clustering. We perform rigorous experimentation and ablations (including on where to retrieve from, how much to retrieve, and how to combine information), and validate our results on several datasets including out-of-distribution domains, demonstrating state-of-art results.
翻译:暂无翻译