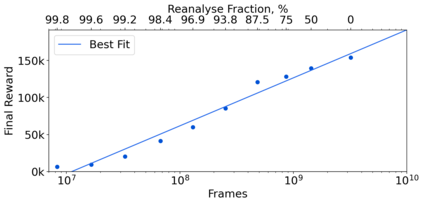
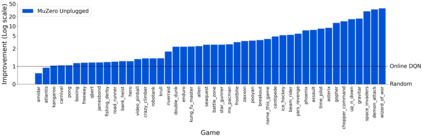
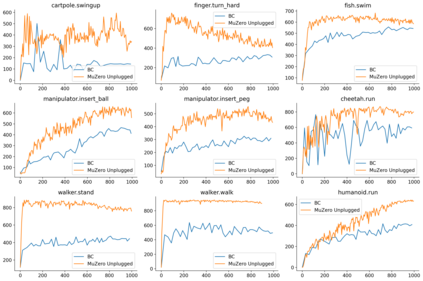
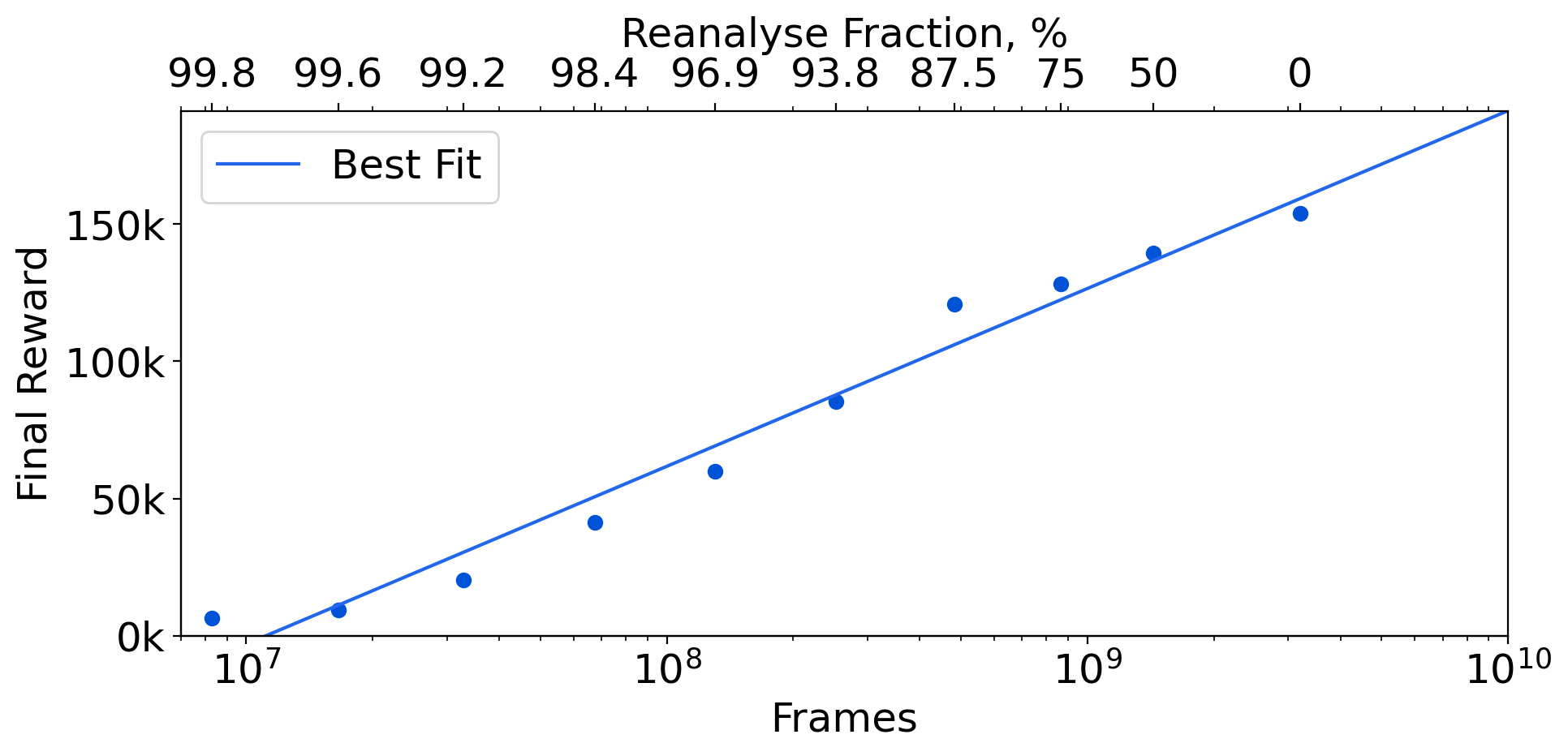
Learning efficiently from small amounts of data has long been the focus of model-based reinforcement learning, both for the online case when interacting with the environment and the offline case when learning from a fixed dataset. However, to date no single unified algorithm could demonstrate state-of-the-art results in both settings. In this work, we describe the Reanalyse algorithm which uses model-based policy and value improvement operators to compute new improved training targets on existing data points, allowing efficient learning for data budgets varying by several orders of magnitude. We further show that Reanalyse can also be used to learn entirely from demonstrations without any environment interactions, as in the case of offline Reinforcement Learning (offline RL). Combining Reanalyse with the MuZero algorithm, we introduce MuZero Unplugged, a single unified algorithm for any data budget, including offline RL. In contrast to previous work, our algorithm does not require any special adaptations for the off-policy or offline RL settings. MuZero Unplugged sets new state-of-the-art results in the RL Unplugged offline RL benchmark as well as in the online RL benchmark of Atari in the standard 200 million frame setting.
翻译:从少量数据中高效学习长期以来一直是基于模型的强化学习的重点,无论是在与环境互动时的在线案例,还是在从固定数据集学习时的离线案例,都是基于小量数据的强化学习的示范学习的重点。然而,迄今为止,没有任何单一的统一算法能够显示两种设置中的最新艺术结果。在这项工作中,我们描述了使用基于模型的政策和价值改进操作员计算现有数据点的新的改进培训目标的“再分析算法”,从而允许对不同程度不同的数据预算进行有效学习。我们进一步表明,“再分析”也可以用于在不进行任何环境互动的情况下从演示中完全学习。在离线强化学习(脱线RL)中也是如此。将“再分析”与“MuZero Unpleted”合并,这是包括离线RL在内的任何数据预算的单一统一算法。与以前的工作相比,我们的算法并不要求对离线或离线 RL 设置的离线设置作任何特殊调整。 Muzero Uncredated 设置了RL 新的最新状态结果,在离线的RL 基准框中,以及在线基准设置为200万基准。