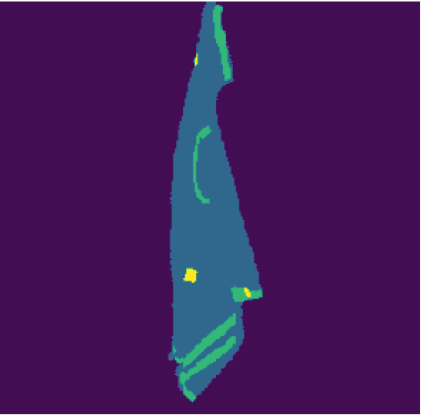
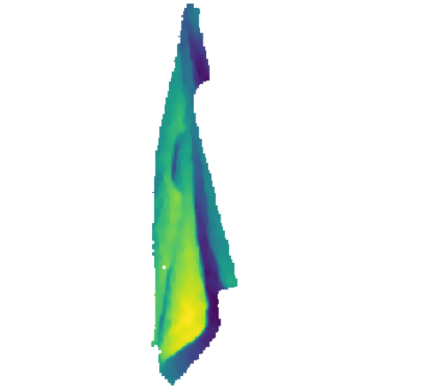
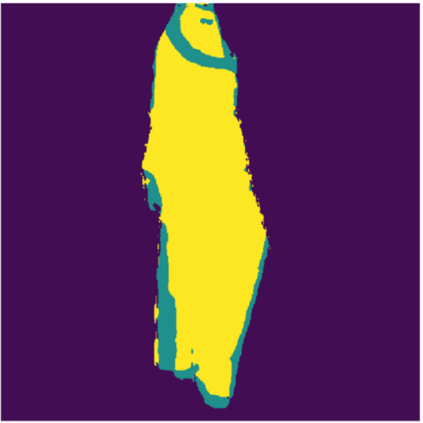
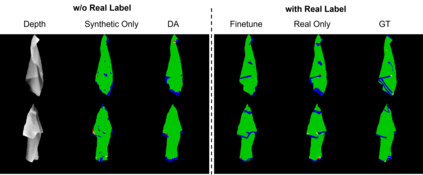
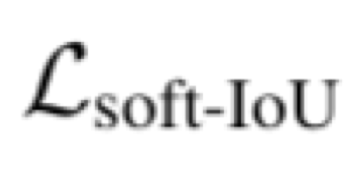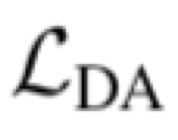Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.
翻译:从单一深度图像中自动探测可捕取的区域,这是布局操纵的一个关键要素。布质变形的巨大变异促使目前大多数方法侧重于确定具体的掌握点,而不是语义部分,因为当地区域的外观和深度变化较小,比较大的区域更容易建模;然而,布叠或协助的布装等任务需要识别较大的部分,如含有比点更多信息多于点点的语义边缘等更广大部分,因此,本文件的第一个目标是解决仅用深度图像才能在变化服装中用深度图像进行精细区域探测的问题。作为概念的证明,我们采用T恤衫的做法,并界定到不同程度的6个语义区域,包括地方区域的外观和深度的外观,比较大的区域更小,更便于模拟。然而,布叠或协助的布叠装等任务需要识别较大部分,例如带有比点更多信息的语系或辅助调。我们工作的第二个贡献涉及我们培训拟议网络所需的监督程度。虽然大多数方法都是通过将真实和合成的描述合并来探测定位点。作为概念的证明,作为概念的证明,我们为T恤、T恤、袖袖、袖、袖袖袖袖袖袖袖袖袖袖袖袖袖袖袖袖袖、袖、袖、袖、袖、袖、袖、袖、袖、袖、袖的网络边缘的网络边缘的网络边缘边缘边边边边边边边边边边边边边边边边边边边边边边边边边边边缘边缘边缘的六区域,我们不限制,我们无视的六区域界定的六区域界定的六区域界定、用的真正培训战略、我们无视限制,我们无视实际培训、我们不理、我们不理、我们不理、我们不理、我们不理、我们不理解、我们不理、我们不理、我们不理解、我们不理解、用的真正培训、我们不理解、我们不深战略、我们不理解、用真正、用真正、我们不亚、用真正、我们不深、用、我们不深、我们不深、我们不深、我们不深、我们不深、我们不深、我们不深、我们不深、我们不深、用、我们不深、我们真正、我们真正、我们真正、我们用、我们不深、用、我们用、用、用、我们正、我们正、我们正、