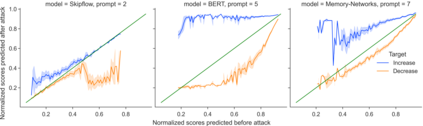
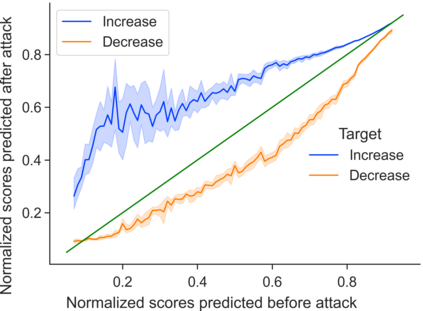
Deep-learning based Automatic Essay Scoring (AES) systems are being actively used by states and language testing agencies alike to evaluate millions of candidates for life-changing decisions ranging from college applications to visa approvals. However, little research has been put to understand and interpret the black-box nature of deep-learning based scoring algorithms. Previous studies indicate that scoring models can be easily fooled. In this paper, we explore the reason behind their surprising adversarial brittleness. We utilize recent advances in interpretability to find the extent to which features such as coherence, content, vocabulary, and relevance are important for automated scoring mechanisms. We use this to investigate the oversensitivity i.e., large change in output score with a little change in input essay content) and overstability i.e., little change in output scores with large changes in input essay content) of AES. Our results indicate that autoscoring models, despite getting trained as "end-to-end" models with rich contextual embeddings such as BERT, behave like bag-of-words models. A few words determine the essay score without the requirement of any context making the model largely overstable. This is in stark contrast to recent probing studies on pre-trained representation learning models, which show that rich linguistic features such as parts-of-speech and morphology are encoded by them. Further, we also find that the models have learnt dataset biases, making them oversensitive. To deal with these issues, we propose detection-based protection models that can detect oversensitivity and overstability causing samples with high accuracies. We find that our proposed models are able to detect unusual attribution patterns and flag adversarial samples successfully.
翻译:州和语言测试机构都积极使用基于深学习的自动读取 Scorning (AES) 系统来评估数百万名候选人参加从大学申请到签证审批等改变人生的决定。 然而,几乎没有研究来理解和解释深学习的评分算法的黑箱性质。 以前的研究表明, 评分模式很容易被愚弄。 在本文中, 我们探索了它们惊人的对抗性细小性( AES) 背后的原因。 我们利用最近在可解释性方面的进展, 以找出诸如一致性、 内容、 词汇和相关性等特征对于自动评分机制的重要性。 我们用这个来调查过度敏感度( 即: 产出评分的大幅变化, 投入论文内容稍有改变) 和过度可理解性( ) 。 我们的评分模型尽管被训练为“ 端对端” 模型, 但也发现它们比BERT更丰富的背景嵌嵌入模型, 表现得像袋词模型。 我们用几个字来决定论文评分, 而没有过分的评分数, 使任何选择的评分 模式 能够进行最接近的 。