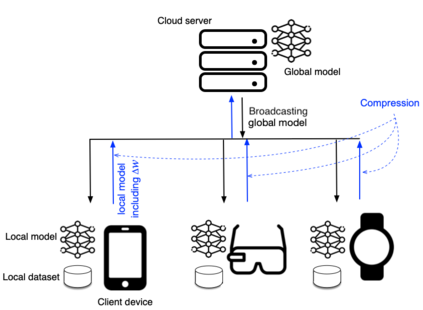
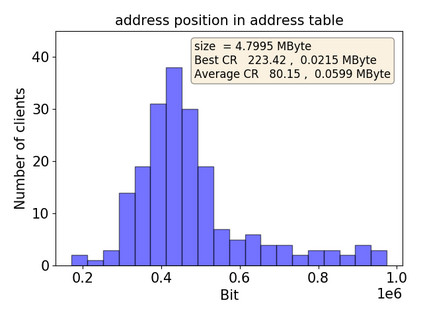
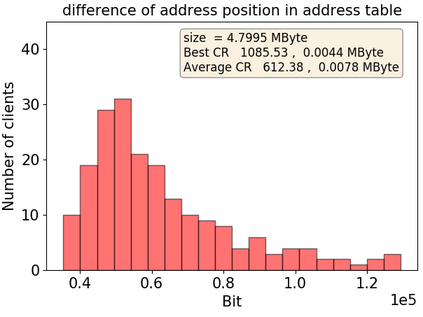
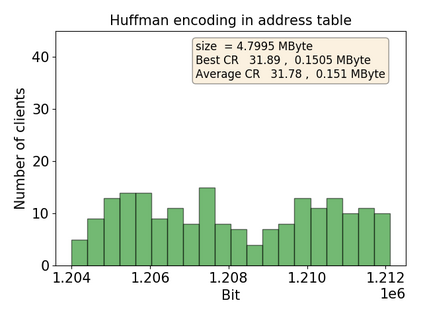
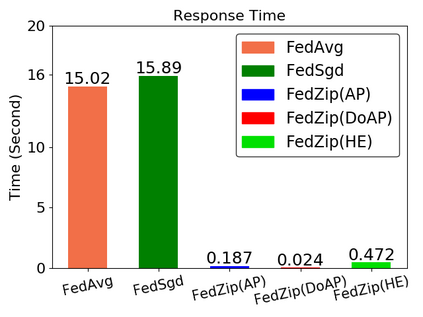
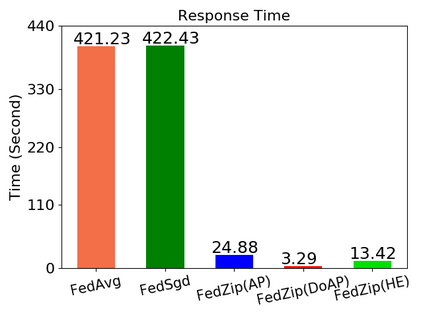
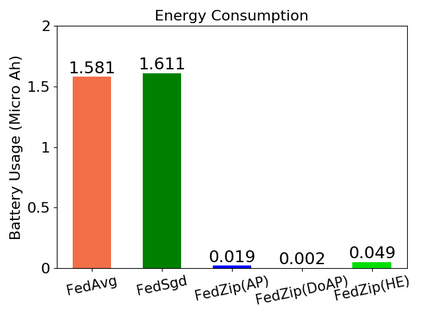
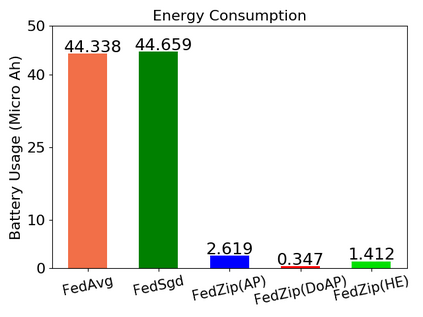
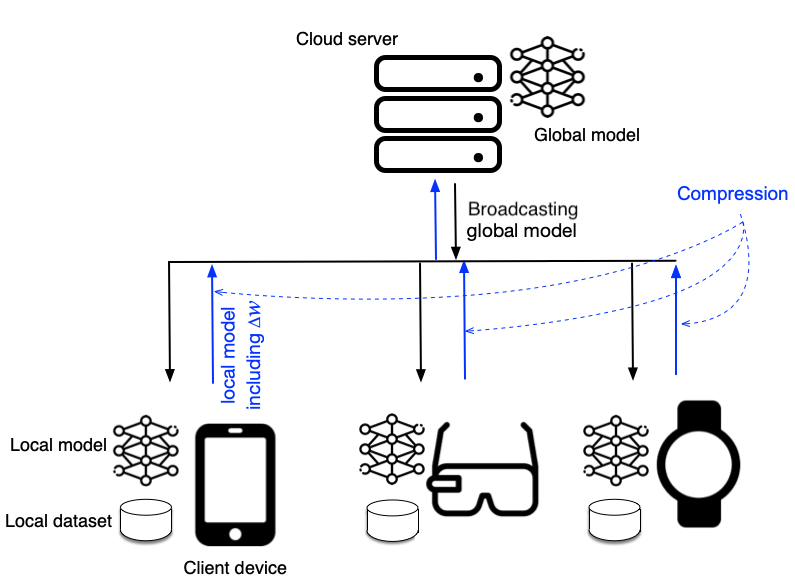
Federated Learning marks a turning point in the implementation of decentralized machine learning (especially deep learning) for wireless devices by protecting users' privacy and safeguarding raw data from third-party access. It assigns the learning process independently to each client. First, clients locally train a machine learning model based on local data. Next, clients transfer local updates of model weights and biases (training data) to a server. Then, the server aggregates updates (received from clients) to create a global learning model. However, the continuous transfer between clients and the server increases communication costs and is inefficient from a resource utilization perspective due to the large number of parameters (weights and biases) used by deep learning models. The cost of communication becomes a greater concern when the number of contributing clients and communication rounds increases. In this work, we propose a novel framework, FedZip, that significantly decreases the size of updates while transferring weights from the deep learning model between clients and their servers. FedZip implements Top-z sparsification, uses quantization with clustering, and implements compression with three different encoding methods. FedZip outperforms state-of-the-art compression frameworks and reaches compression rates up to 1085x, and preserves up to 99% of bandwidth and 99% of energy for clients during communication.
翻译:联邦学习联合会标志着一个转折点,通过保护用户隐私和保护第三方访问的原始数据,对无线设备实施分散的机器学习(特别是深层学习),保护用户隐私,保护用户的隐私,保护第三方访问的原始数据,从而将学习过程独立分配给每个客户。首先,客户在当地培训基于当地数据的机器学习模式。接着,客户将模型重量和偏向(培训数据)的当地更新转移到服务器。然后,服务器汇总更新(客户收到客户的接收),以创建一个全球学习模式。然而,客户和服务器之间的连续传输增加了通信成本,从资源利用的角度来说效率低下,因为深层学习模式使用了大量参数(重量和偏差)。当贡献客户和通信轮数增加时,通信成本就成为一个更大的问题。在此工作中,我们提出了一个新的框架,即FedZip,在客户及其服务器之间将深层学习模式的重量转移的同时,大幅降低更新规模。FedZip实施Top-z 通缩缩放,在集群中使用夸大化,并以三种不同的编码方法实施压缩压缩。FedZip 超越了提供艺术压缩框架的状态,在99 % 和压缩率期间将客户的压缩率提高到1085 。