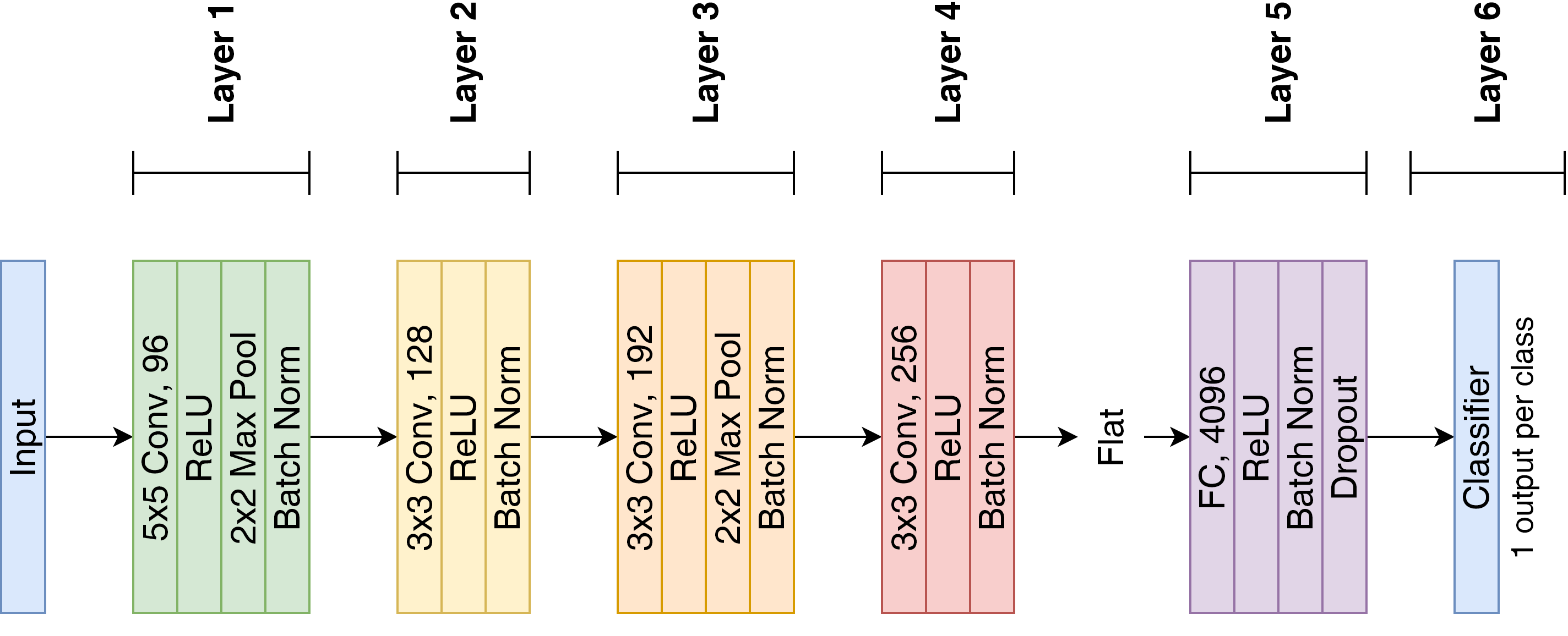
Features extracted from Deep Neural Networks (DNNs) have proven to be very effective in the context of Content Based Image Retrieval (CBIR). In recent work, biologically inspired \textit{Hebbian} learning algorithms have shown promises for DNN training. In this contribution, we study the performance of such algorithms in the development of feature extractors for CBIR tasks. Specifically, we consider a semi-supervised learning strategy in two steps: first, an unsupervised pre-training stage is performed using Hebbian learning on the image dataset; second, the network is fine-tuned using supervised Stochastic Gradient Descent (SGD) training. For the unsupervised pre-training stage, we explore the nonlinear Hebbian Principal Component Analysis (HPCA) learning rule. For the supervised fine-tuning stage, we assume sample efficiency scenarios, in which the amount of labeled samples is just a small fraction of the whole dataset. Our experimental analysis, conducted on the CIFAR10 and CIFAR100 datasets shows that, when few labeled samples are available, our Hebbian approach provides relevant improvements compared to various alternative methods.
翻译:从深神经网络(Deep Neal Inform Inform Inform Internets)中提取的特征证明在内容图像检索检索(CBIR)方面非常有效。在最近的工作中,生物启发的学习算法显示了对DNN培训的承诺。在这一贡献中,我们研究了这种算法在为CBIR任务开发地貌提取器方面的表现。具体地说,我们从两个步骤中考虑半监督的学习战略:第一,利用Hebbian在图像数据集方面的学习进行一个未经监督的训练前阶段;第二,利用受监督的Stochatical Egradient Egre(SGD)培训对网络进行微调。对于未经监督的训练前阶段,我们探索了非线性 Hebbian主要组成部分分析(HPCA)的学习规则。对于受监督的微调阶段,我们假设了抽样效率假设,其中标定样品的数量只是整个数据集的一小部分。我们在CIFAR10和CIFAR100数据集上进行的实验分析显示,当很少有标签样品时,我们用不同的方法来比较。