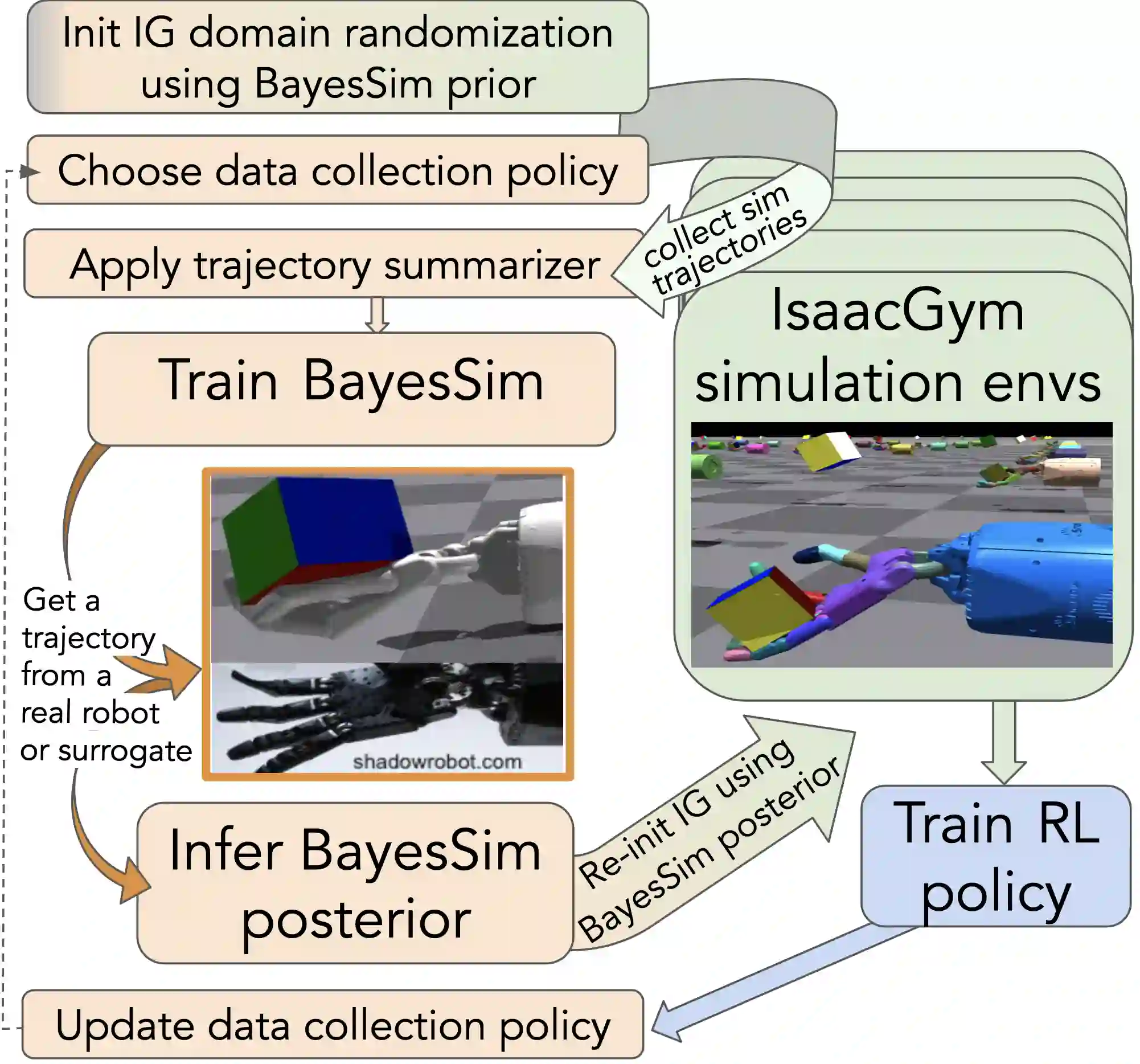
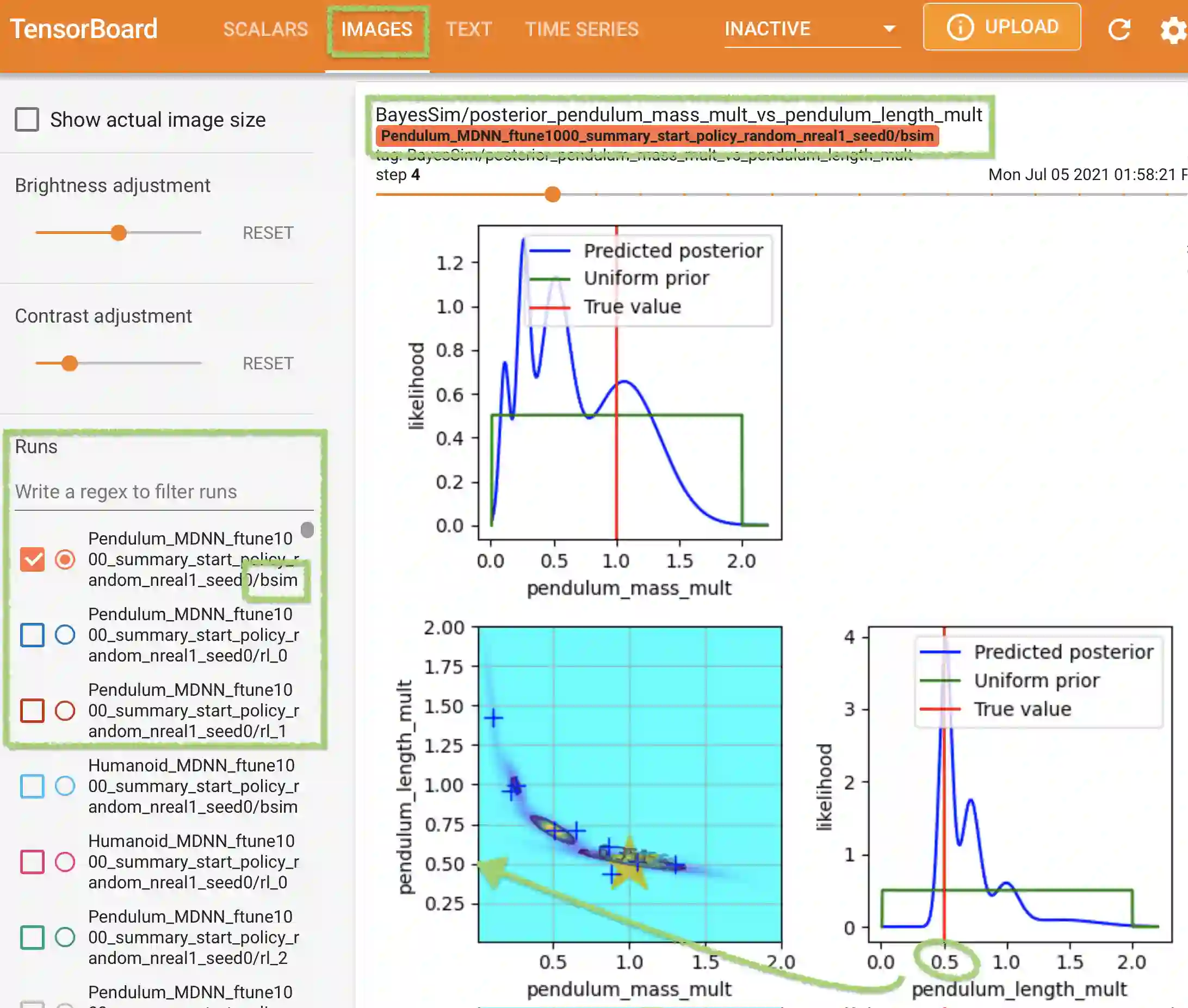
BayesSim is a statistical technique for domain randomization in reinforcement learning based on likelihood-free inference of simulation parameters. This paper outlines BayesSimIG: a library that provides an implementation of BayesSim integrated with the recently released NVIDIA IsaacGym. This combination allows large-scale parameter inference with end-to-end GPU acceleration. Both inference and simulation get GPU speedup, with support for running more than 10K parallel simulation environments for complex robotics tasks that can have more than 100 simulation parameters to estimate. BayesSimIG provides an integration with TensorBoard to easily visualize slices of high-dimensional posteriors. The library is built in a modular way to support research experiments with novel ways to collect and process the trajectories from the parallel IsaacGym environments.
翻译:BayesSim是一种根据模拟参数的无概率推断,在强化学习中进行域随机化的统计技术。本文概述了BayesSimIG:一个提供BayesSim与最近发行的NVIDIA IsaacGym集成的图书馆。这种结合可以使用端到端GPU加速度进行大型参数推断。两种推论和模拟都加速了GPU,支持运行超过10K的平行模拟环境,用于可估计超过100个模拟参数的复杂机器人任务。BayesSimIG提供了与TensorBoard的集成,以易于视觉化高维外层片。图书馆以模块方式建成,以支持研究实验,以新的方式收集和处理平行的IsacGym环境的轨迹。