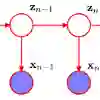
Part of speech tagging in zero-resource settings can be an effective approach for low-resource languages when no labeled training data is available. Existing systems use two main techniques for POS tagging i.e. pretrained multilingual large language models(LLM) or project the source language labels into the zero resource target language and train a sequence labeling model on it. We explore the latter approach using the off-the-shelf alignment module and train a hidden Markov model(HMM) to predict the POS tags. We evaluate transfer learning setup with English as a source language and French, German, and Spanish as target languages for part-of-speech tagging. Our conclusion is that projected alignment data in zero-resource language can be beneficial to predict POS tags.
翻译:暂无翻译