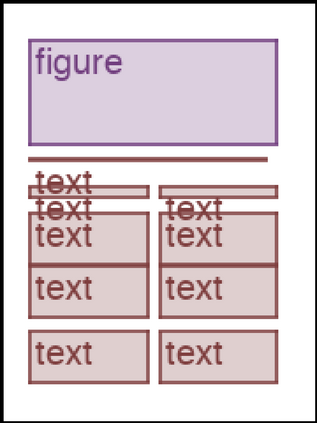
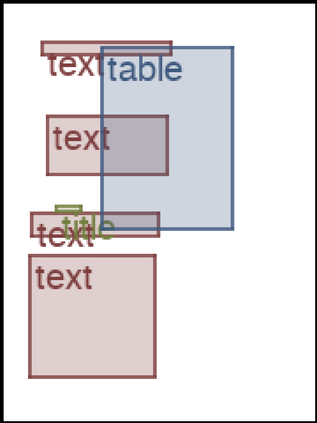
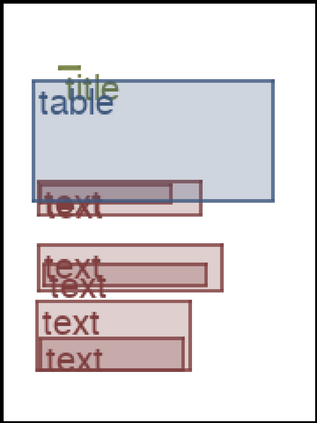
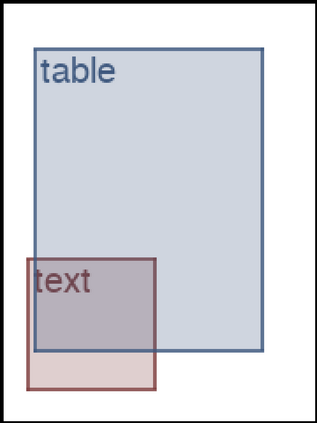
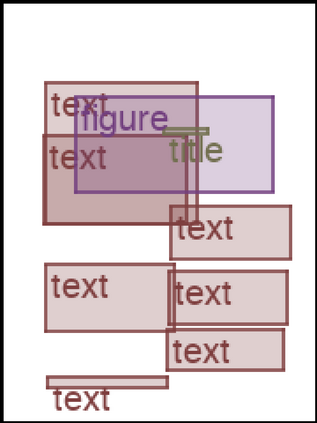
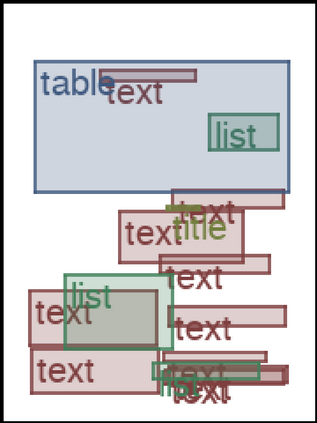
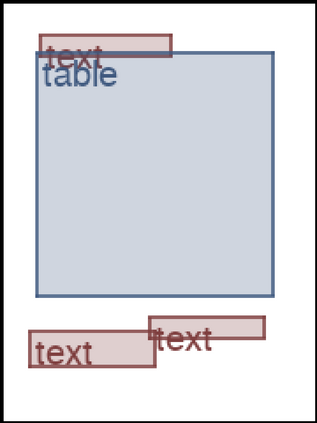
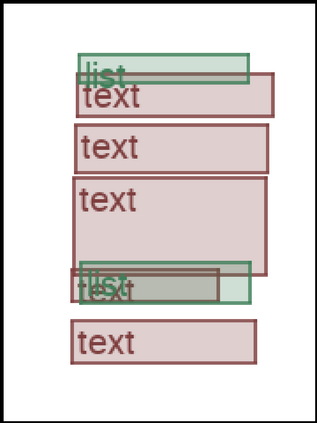
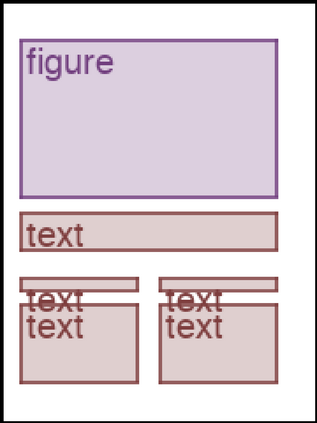
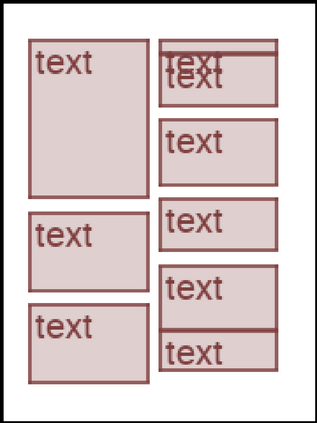
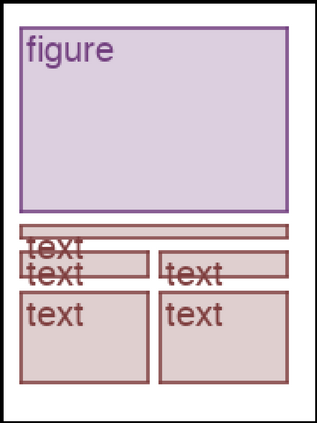
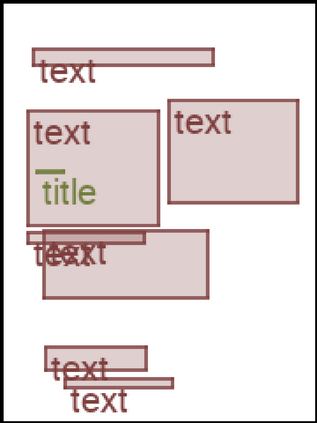
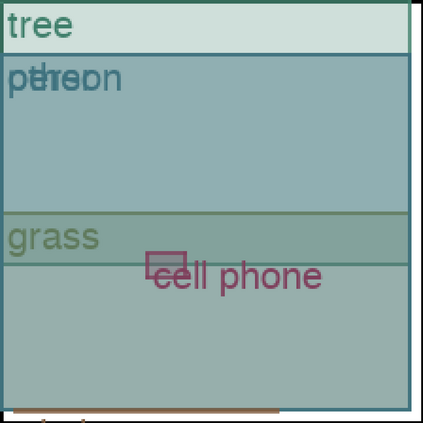
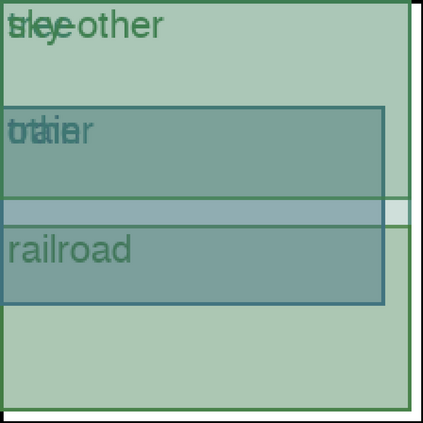
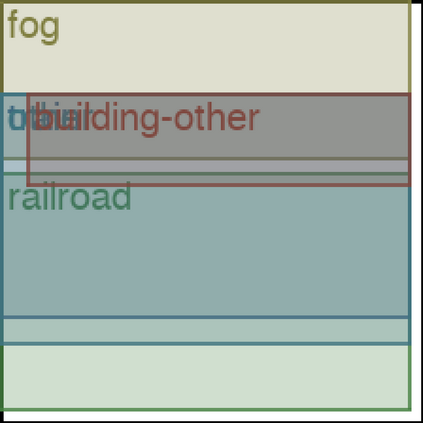
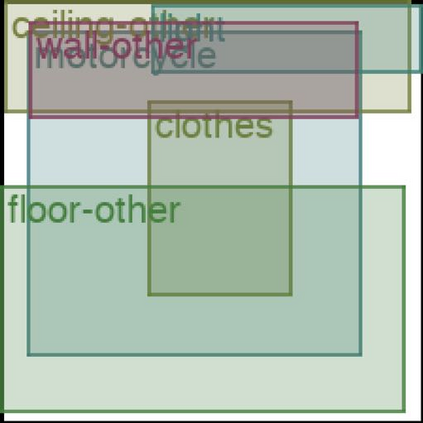
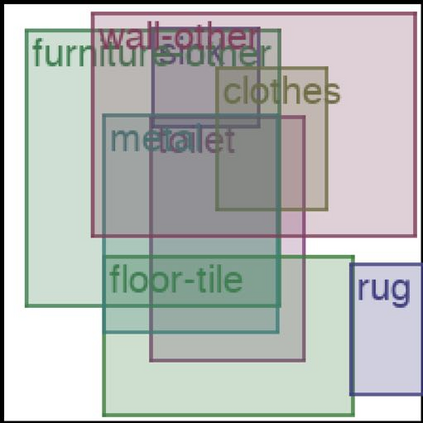
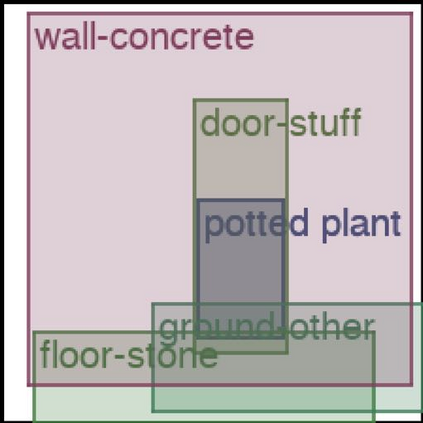
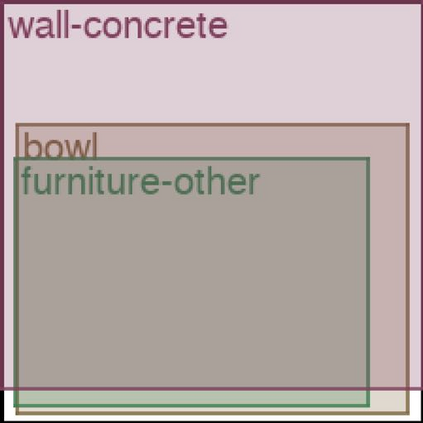
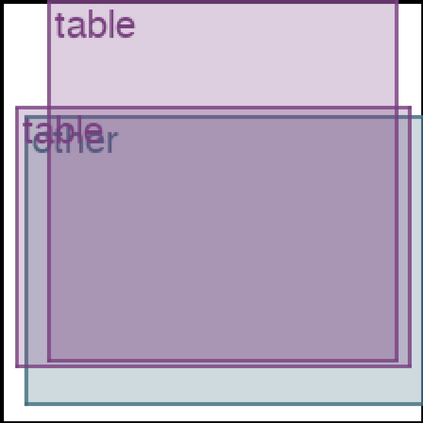
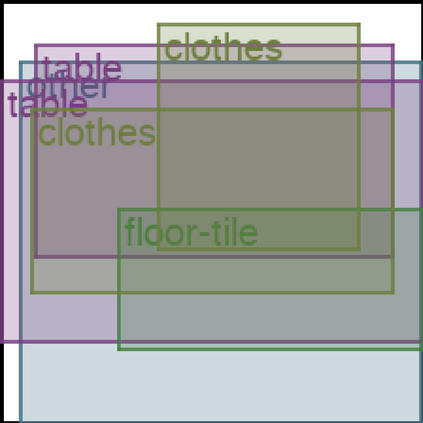
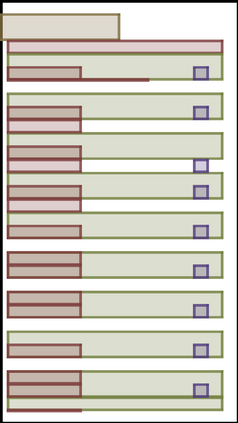
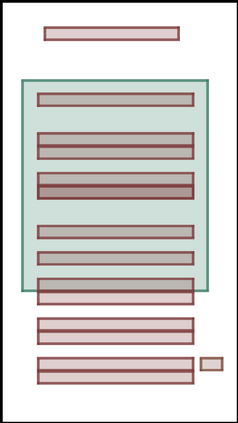
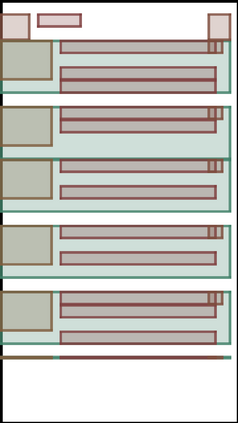
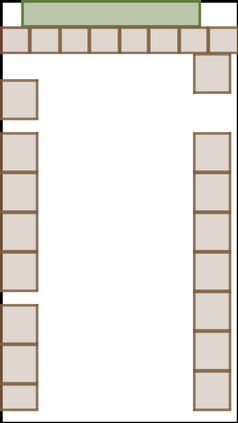
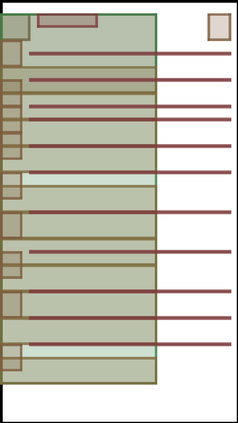
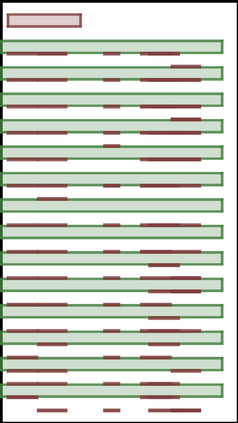
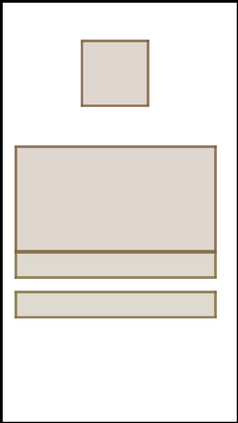
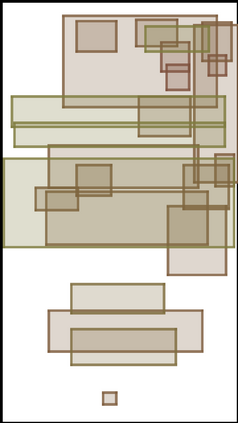
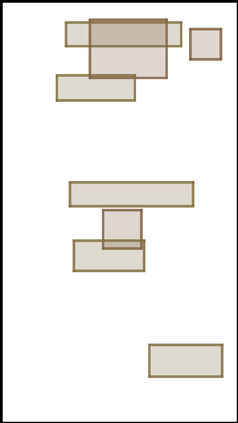
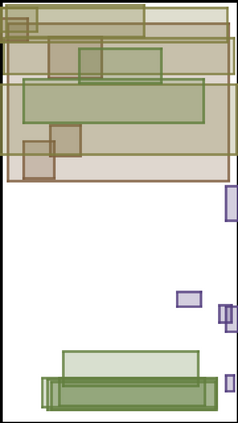
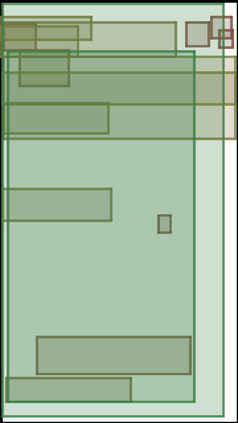
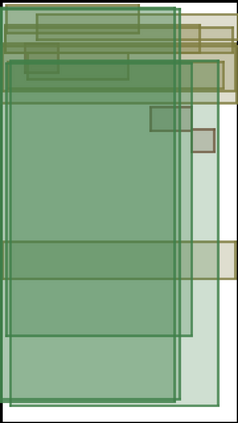
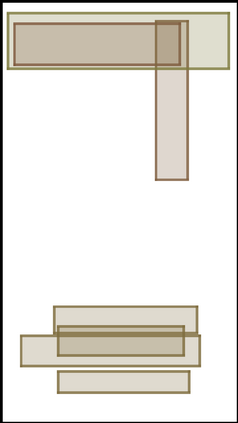
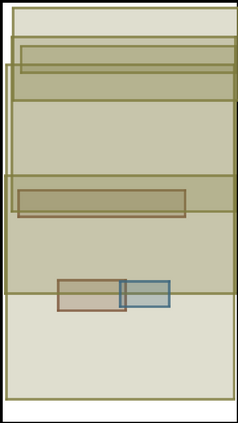
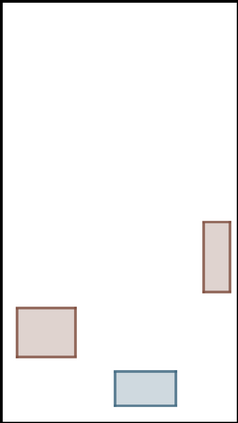
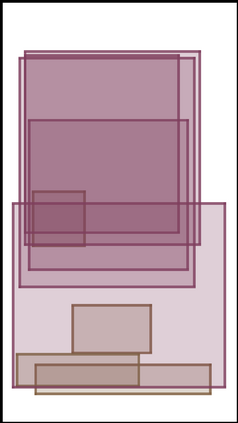
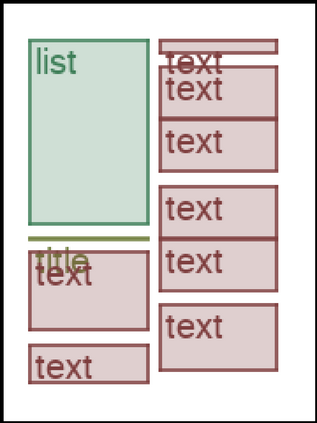
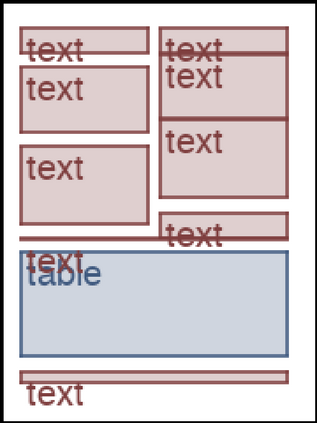
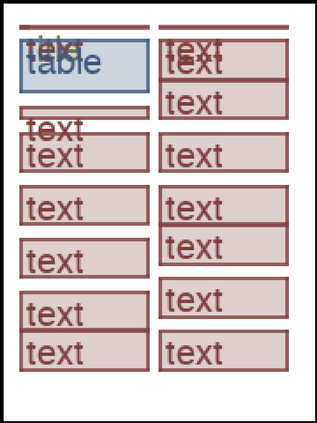
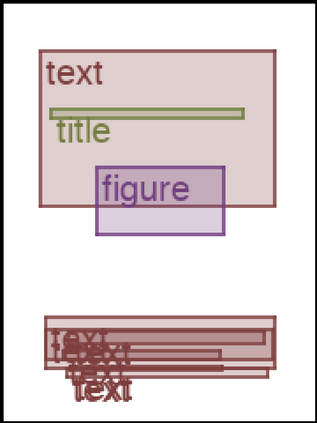
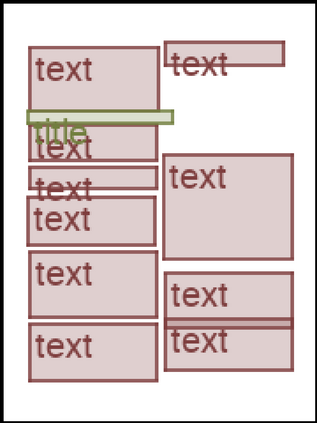
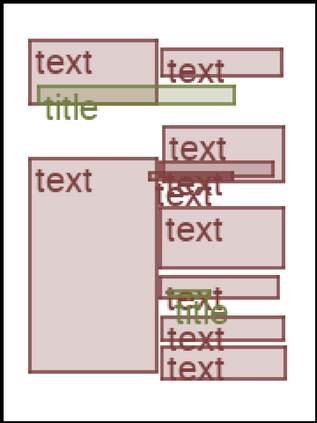
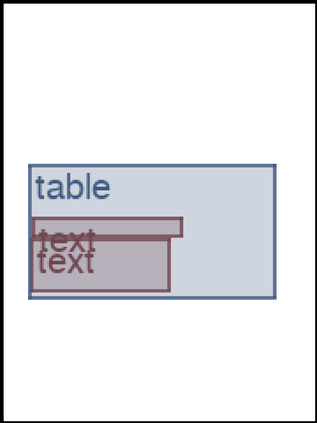
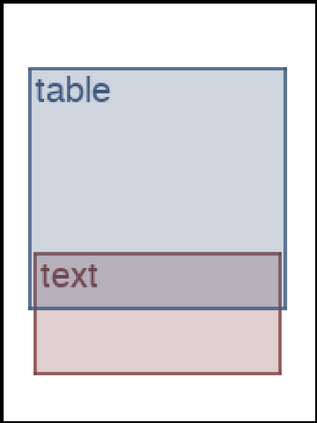
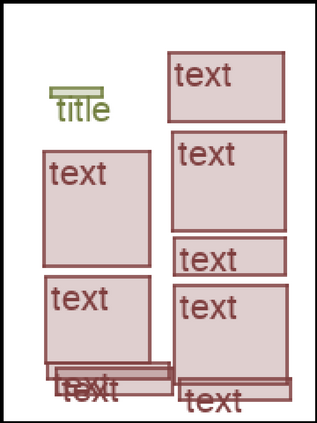
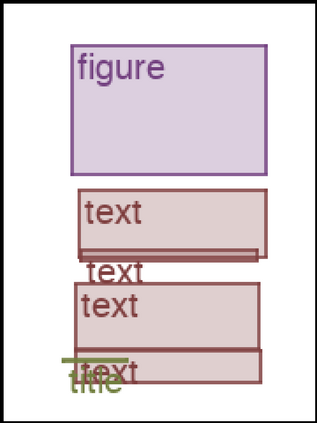
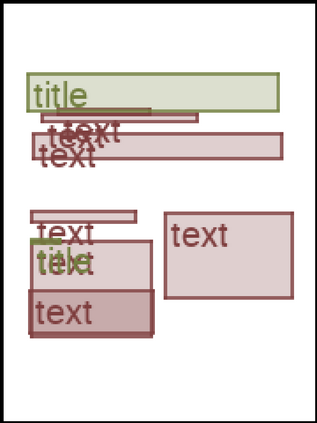
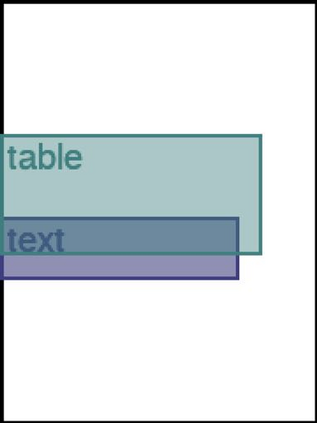
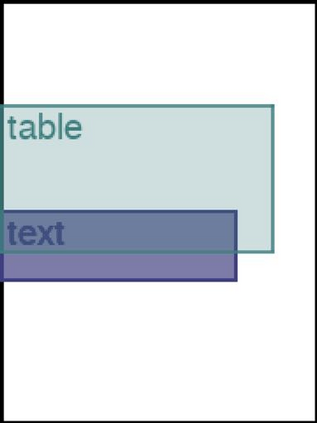
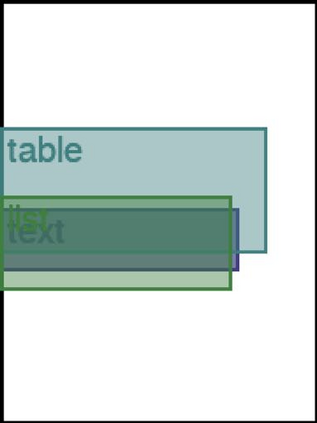
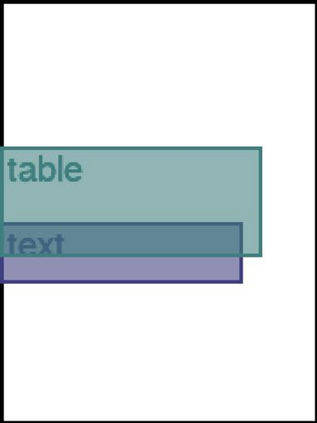
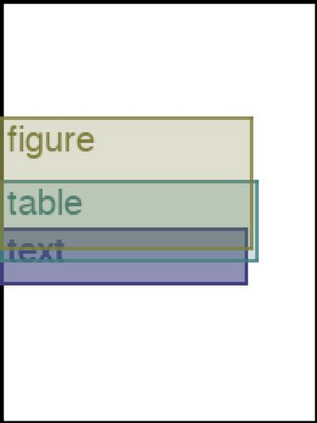
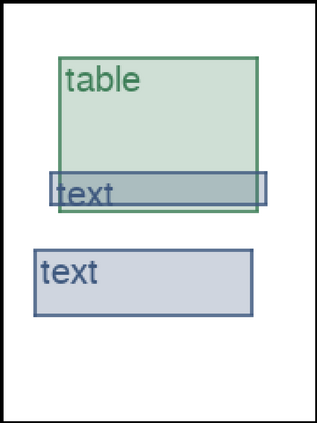
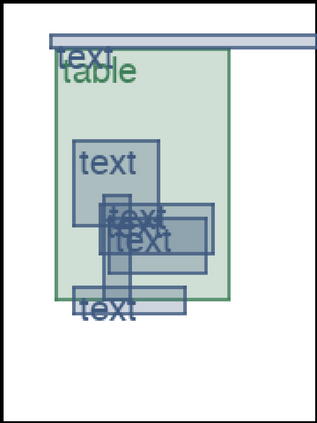
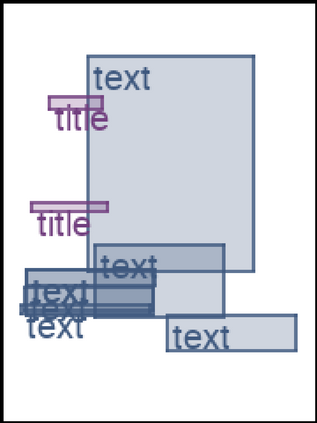
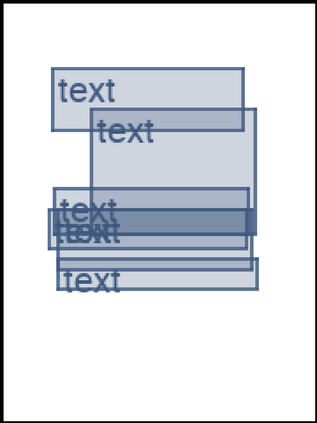
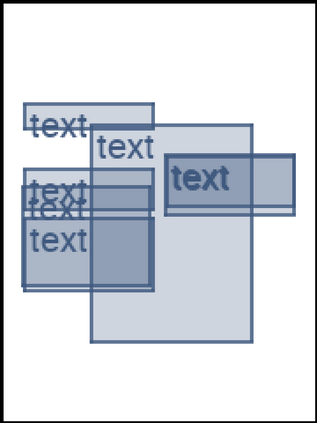
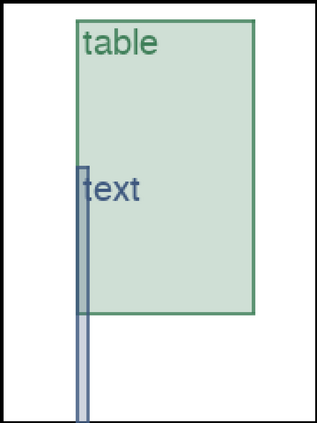
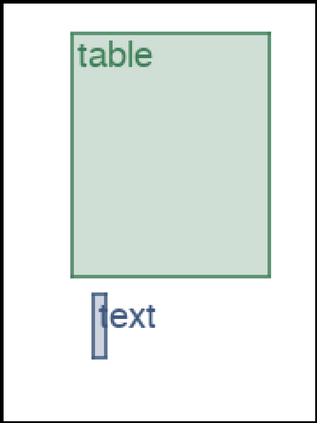
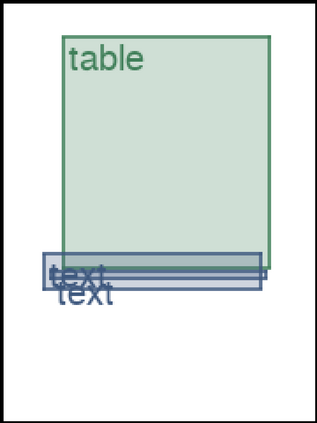
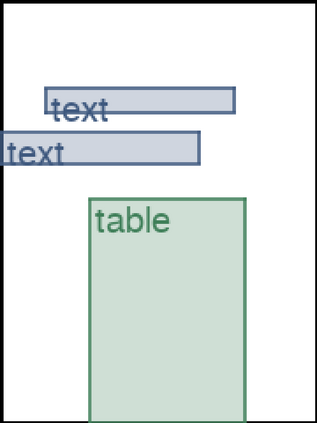
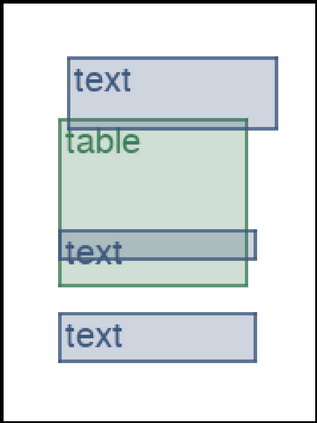
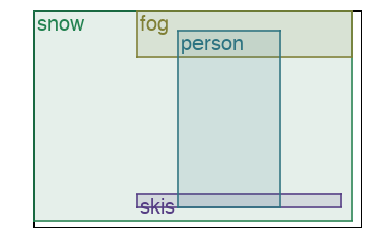
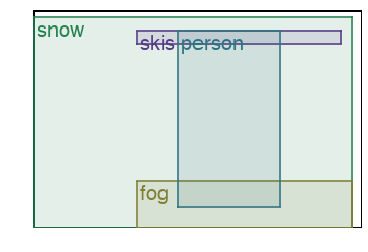
We address the problem of layout generation for diverse domains such as images, documents, and mobile applications. A layout is a set of graphical elements, belonging to one or more categories, placed together in a meaningful way. Generating a new layout or extending an existing layout requires understanding the relationships between these graphical elements. To do this, we propose a novel framework, LayoutTransformer, that leverages a self-attention based approach to learn contextual relationships between layout elements and generate layouts in a given domain. The proposed model improves upon the state-of-the-art approaches in layout generation in four ways. First, our model can generate a new layout either from an empty set or add more elements to a partial layout starting from an initial set of elements. Second, as the approach is attention-based, we can visualize which previous elements the model is attending to predict the next element, thereby providing an interpretable sequence of layout elements. Third, our model can easily scale to support both a large number of element categories and a large number of elements per layout. Finally, the model also produces an embedding for various element categories, which can be used to explore the relationships between the categories. We demonstrate with experiments that our model can produce meaningful layouts in diverse settings such as object bounding boxes in scenes (COCO bounding boxes), documents (PubLayNet), and mobile applications (RICO dataset).
翻译:我们处理图象、文档和移动应用程序等不同域的布局生成问题。 一个布局是一组属于一个或一个以上类别的图形元素,以有意义的方式组合在一起。 创建新布局或扩展现有布局需要理解这些图形元素之间的关系。 为此,我们提出一个新的框架,即布局 Transferect, 利用基于自我注意的方法来学习布局元素之间的背景关系,并在一个特定域生成布局。 拟议的模型以四种方式改进了布局生成中最先进的方法。 首先, 我们的模型可以从空集中产生新的布局, 或者从最初的一组元素开始将更多的元素添加到部分布局中。 其次, 由于新布局是以关注为基础的, 我们可以直观地看到模型所要预测的下一个元素的先前要素, 从而提供布局元素的可解释序列。 第三, 我们的模型可以很容易地支持大量的元素类别和每个布局中的许多元素。 最后, 模型还生成了各种元素类别的嵌入布局, 可以用来探索从最初一组元素中开始的部分布局。 其次, 由于该方法基于注意, 我们可以直观的布局, 我们用移动的框框框中, 我们展示了我们所制作了我们的模型, 我们的模型, 将展示中, 我们的模型将产生了这些图框框中, 将产生了各种模型, 将产生了各种模型, 并装成成成成成为 。