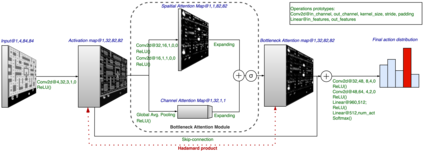
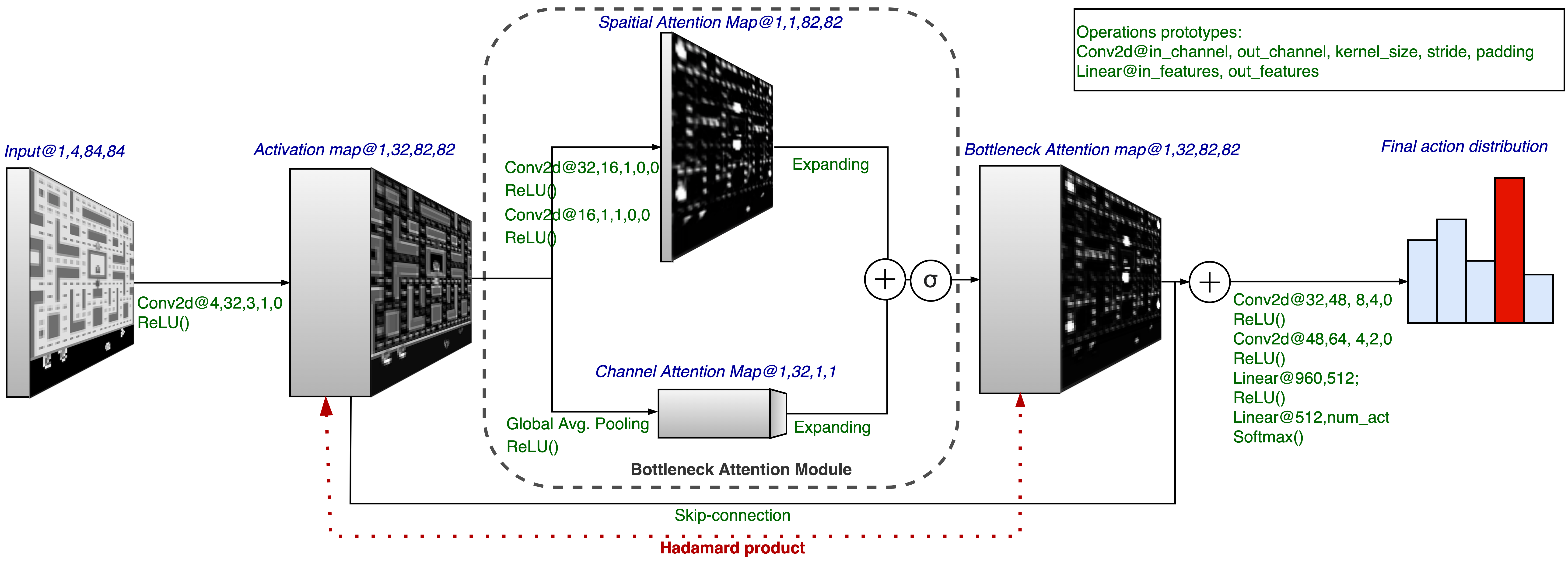
Robustness to adversarial perturbations has been explored in many areas of computer vision. This robustness is particularly relevant in vision-based reinforcement learning, as the actions of autonomous agents might be safety-critic or impactful in the real world. We investigate the susceptibility of vision-based reinforcement learning agents to gradient-based adversarial attacks and evaluate a potential defense. We observe that Bottleneck Attention Modules (BAM) included in CNN architectures can act as potential tools to increase robustness against adversarial attacks. We show how learned attention maps can be used to recover activations of a convolutional layer by restricting the spatial activations to salient regions. Across a number of RL environments, BAM-enhanced architectures show increased robustness during inference. Finally, we discuss potential future research directions.
翻译:在计算机视觉的许多领域探索了对对抗性干扰的强力。这种强力在基于愿景的强化学习中特别相关,因为自主代理人的行动在现实世界中可能是安全的批评或影响性的。我们调查了基于愿景的强化学习代理人对基于梯度的对抗性攻击的易感性,并评估了潜在的防御能力。我们发现,CNN结构中包含的瓶颈关注模块(BAM)可以成为增强抵御对抗性攻击的有力性的潜在工具。我们展示了如何通过将空间激活限制在显要区域来利用所学的注意地图来恢复卷轴层的激活。在一些区域,BAM增强的建筑在推断过程中表现出了更强的强力。最后,我们讨论了潜在的未来研究方向。