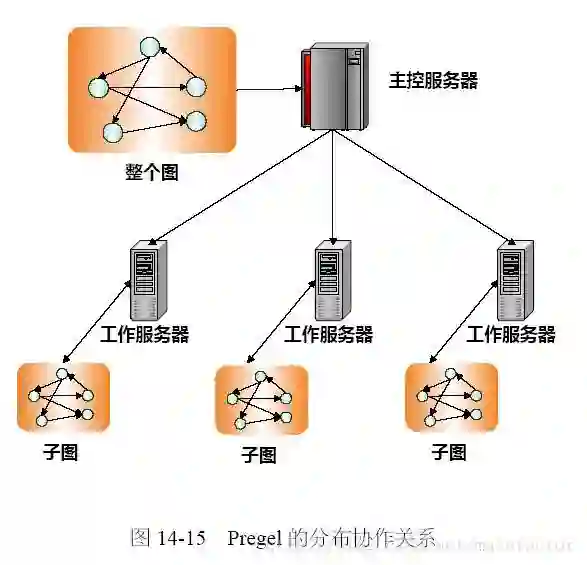
Massive graphs, such as online social networks and communication networks, have become common today. To efficiently analyze such large graphs, many distributed graph computing systems have been developed. These systems employ the "think like a vertex" programming paradigm, where a program proceeds in iterations and at each iteration, vertices exchange messages with each other. However, using Pregel's simple message passing mechanism, some vertices may send/receive significantly more messages than others due to either the high degree of these vertices or the logic of the algorithm used. This forms the communication bottleneck and leads to imbalanced workload among machines in the cluster. In this paper, we propose two effective message reduction techniques: (1)vertex mirroring with message combining, and (2)an additional request-respond API. These techniques not only reduce the total number of messages exchanged through the network, but also bound the number of messages sent/received by any single vertex. We theoretically analyze the effectiveness of our techniques, and implement them on top of our open-source Pregel implementation called Pregel+. Our experiments on various large real graphs demonstrate that our message reduction techniques significantly improve the performance of distributed graph computation.
翻译:大型图表,例如在线社交网络和通信网络,如今已变得司空见惯。为了有效分析这些大型图表,已经开发了许多分布式图表计算系统。这些系统采用了“像顶点一样思考”编程模式,即一个程序在迭代中和每次迭代中相互交换信息。然而,使用Pregel的简单信息传递机制,一些顶点可能发送/接收的信息大大多于其他信息,原因是这些顶点的高度或所用算法的逻辑。这形成了通信瓶颈,导致集体中机器之间工作量的不平衡。在本文中,我们提出了两种有效的信息减少技术:(1) 与信息合并的反向镜和(2) 额外的请求响应 API 。这些技术不仅减少了通过网络交换的信息总数,而且还限制了任何单一的顶点所发送/接收的信息数量。我们从理论上分析了我们的技术的有效性,并在我们公开源的 Pregel + 执行工具的顶端上应用了这些技术。我们在各种大图表上进行的实验展示了我们减少信息绩效的模型。