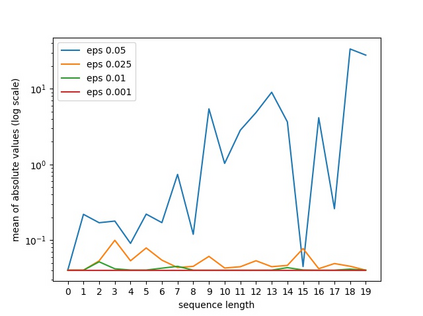
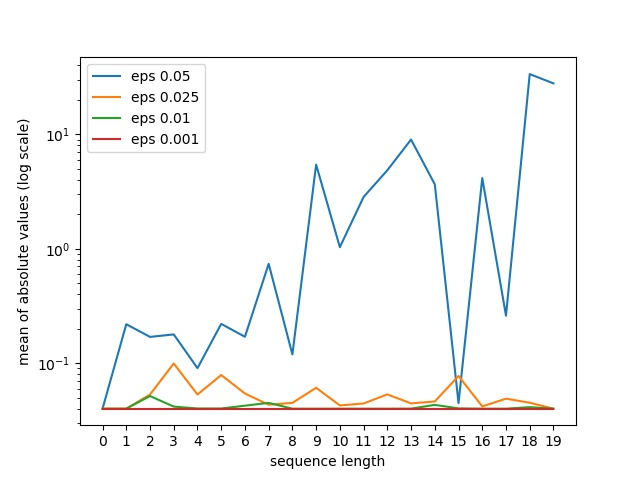
Using pretrained word embeddings has been shown to be a very effective way in improving the performance of natural language processing tasks. In fact almost any natural language tasks that can be thought of has been improved by these pretrained embeddings. These tasks range from sentiment analysis, translation, sequence prediction amongst many others. One of the most successful word embeddings is the Word2vec CBOW model proposed by Mikolov trained by the negative sampling technique. Mai et al. modifies this objective to train CMOW embeddings that are sensitive to word order. We used a modified version of the negative sampling objective for our context words, modelling the context embeddings as a Taylor series of rate matrices. We show that different modes of the Taylor series produce different types of embeddings. We compare these embeddings to their similar counterparts like CBOW and CMOW and show that they achieve comparable performance. We also introduce a novel left-right context split objective that improves performance for tasks sensitive to word order. Our Word2rate model is grounded in a statistical foundation using rate matrices while being competitive in variety of language tasks.
翻译:使用预先训练的字嵌入器已被证明是改进自然语言处理任务绩效的一个非常有效的方法。 事实上,几乎所有自然语言任务都通过这些预先训练的嵌入器得到了改进。 这些任务包括情绪分析、翻译、对许多其他任务进行序列预测等。 最成功的字嵌入器之一是经过负面取样技术培训的Mikolov提出的Word2vec CBOW模型。 Mai 等人对这一目标进行了修改,以培训对文字顺序敏感的CMOW嵌入器。 我们对上下文单词使用了经修改的负抽样目标版本,将上下文嵌入成泰勒序列。 我们显示,泰勒系列的不同模式产生了不同类型的嵌入器。 我们将这些嵌入器与类似类似的方式如CBOW和COPO, 并显示它们取得了相似的性能。 我们还引入了一个新的左侧环境分割目标, 以提高对文字顺序敏感的任务的性能。 我们的Wod2Rate模型以统计基础为基础, 使用有竞争力的汇率矩阵, 并且具有多种语言任务的竞争。