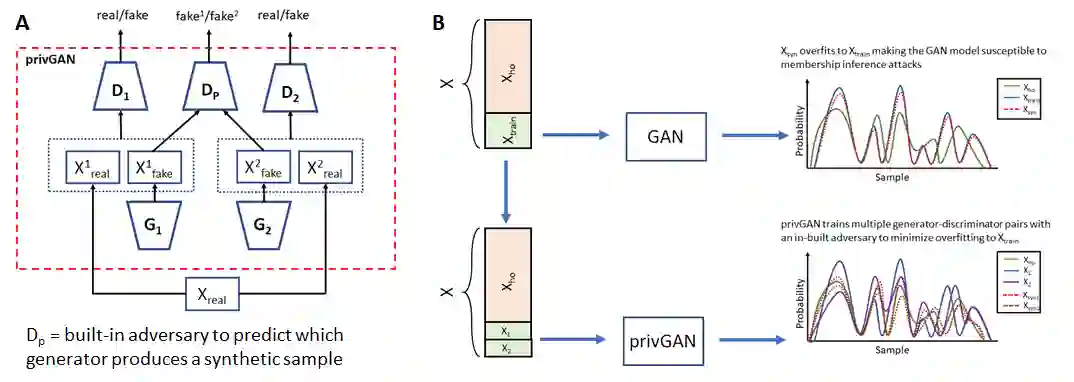
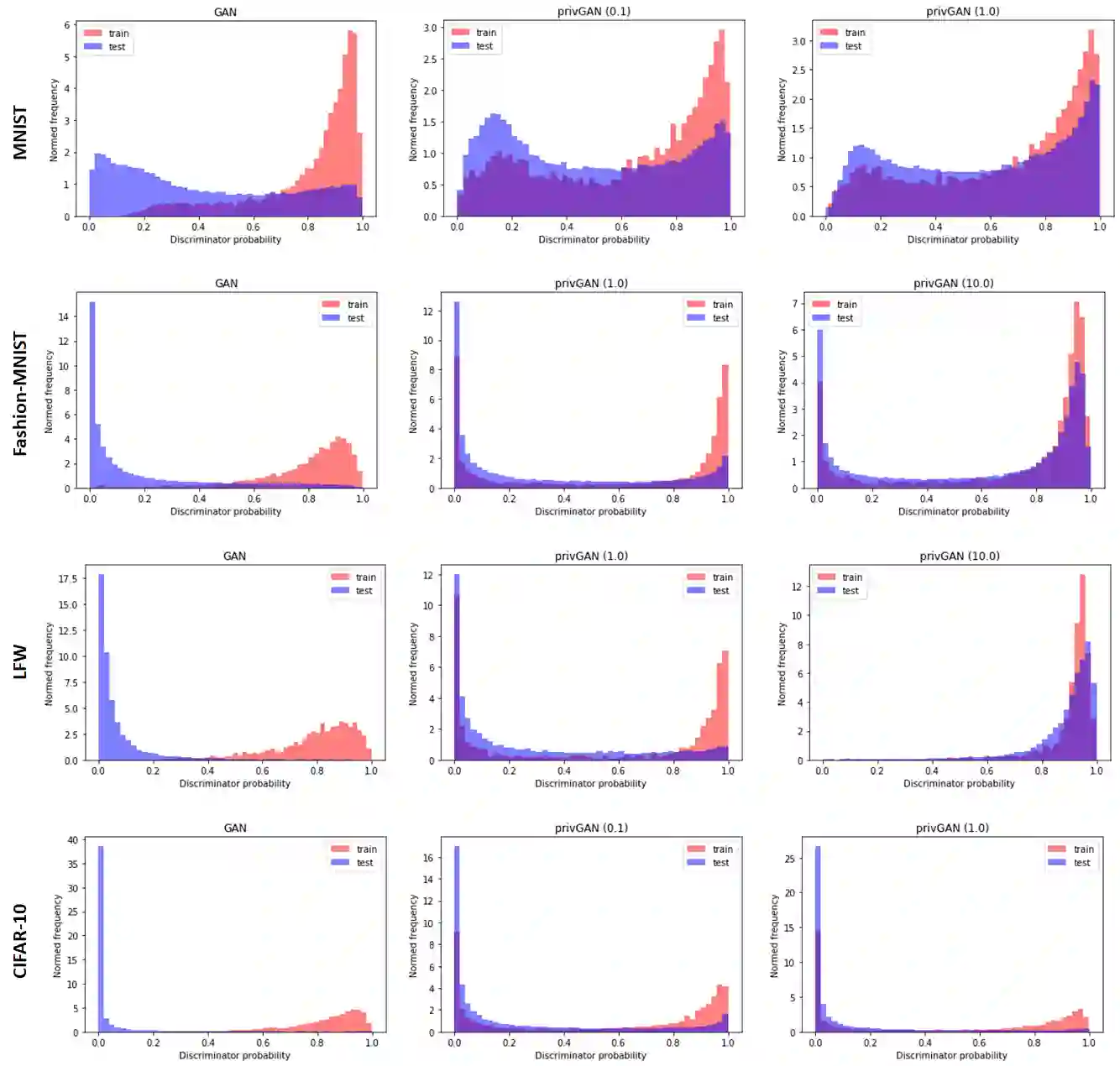
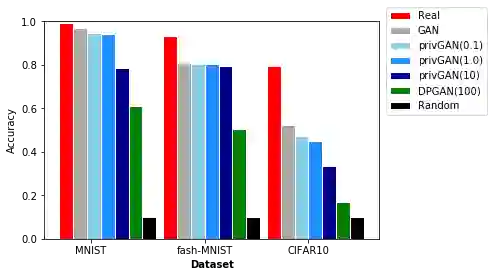
Generative Adversarial Networks (GANs) have made releasing of synthetic images a viable approach to share data without releasing the original dataset. It has been shown that such synthetic data can be used for a variety of downstream tasks such as training classifiers that would otherwise require the original dataset to be shared. However, recent work has shown that the GAN models and their synthetically generated data can be used to infer the training set membership by an adversary who has access to the entire dataset and some auxiliary information. Current approaches to mitigate this problem (such as DPGAN) lead to dramatically poorer generated sample quality than the original non--private GANs. Here we develop a new GAN architecture (privGAN), where the generator is trained not only to cheat the discriminator but also to defend membership inference attacks. The new mechanism provides protection against this mode of attack while leading to negligible loss in downstream performances. In addition, our algorithm has been shown to explicitly prevent overfitting to the training set, which explains why our protection is so effective. The main contributions of this paper are: i) we propose a novel GAN architecture that can generate synthetic data in a privacy preserving manner without additional hyperparameter tuning and architecture selection, ii) we provide a theoretical understanding of the optimal solution of the privGAN loss function, iii) we demonstrate the effectiveness of our model against several white and black--box attacks on several benchmark datasets, iv) we demonstrate on three common benchmark datasets that synthetic images generated by privGAN lead to negligible loss in downstream performance when compared against non--private GANs.
翻译:事实证明,这种合成数据可以用于一系列下游任务,例如培训分类师,否则需要共享原始数据集;然而,最近的工作表明,GAN模型及其合成生成的数据可以用来推断能够使用整个数据集和一些辅助信息的敌手的培训成员构成情况。目前缓解这一问题的方法(如DPGAN)导致生成的样本质量比原非私营GAN质量要差得多。在这里,我们开发了一个新的GAN结构(privGAN),在这种任务中,不仅培训了欺骗歧视者,而且还保护了成员攻击。新机制提供了防范这种攻击模式,同时导致下游业绩损失微乎其微。此外,我们的算法已经表明,我们明确防止过分适应培训成套,这解释了为什么我们的保护如此有效。 本文的主要贡献是:i)我们建议针对GAN基准的黑色模型生成质量质量比原非私营GAN图像质量,在这里不仅训练了欺骗者,而且还训练了捍卫了成员攻击。 新的机制提供了这种攻击模式,同时导致下游业绩的微不足道的损失。 此外,我们的算法表明,当我们对AN基准进行如此有效的保护时,我们的主要贡献是:(i)我们建议针对GAN基准的GAN模型的精确的模型的模型的模型的模型的模型的模型的模型,可以提供一种不让我们的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型的模型在维护了一种演示。