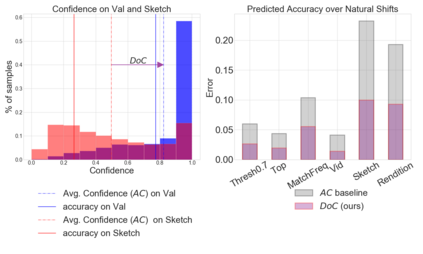
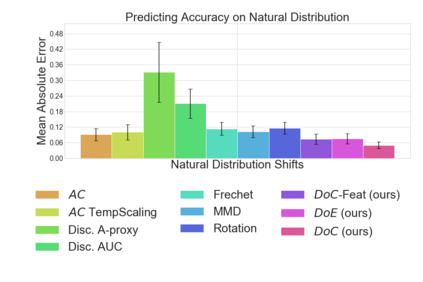
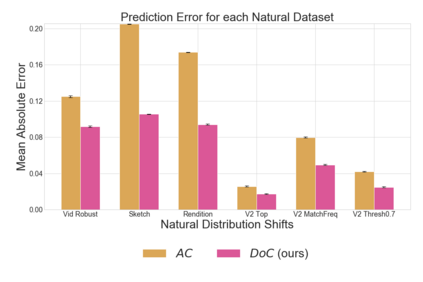
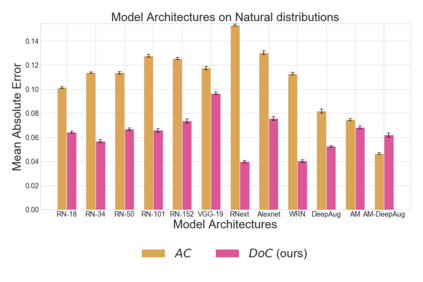
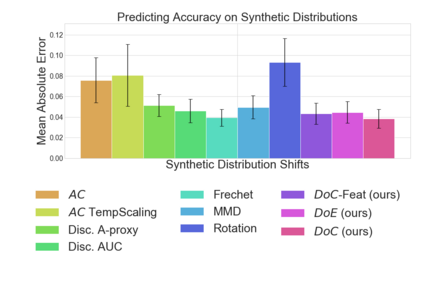
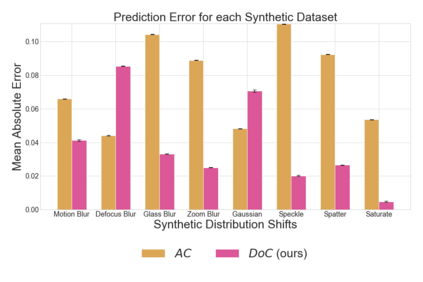
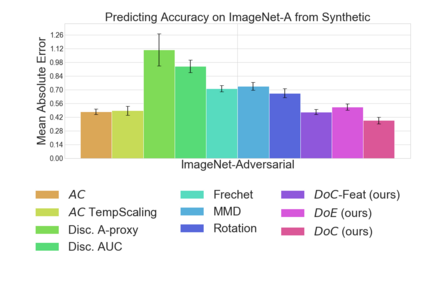
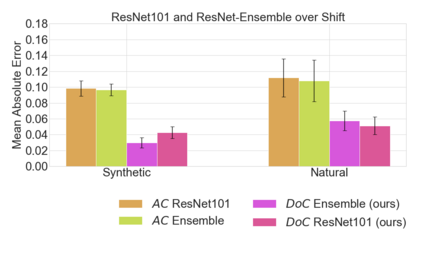
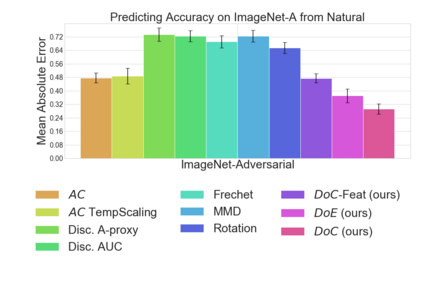
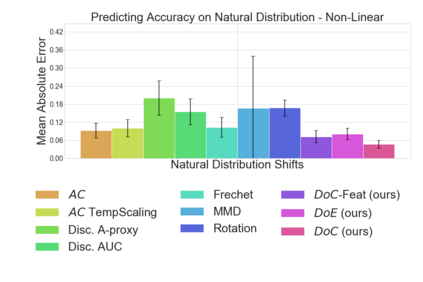
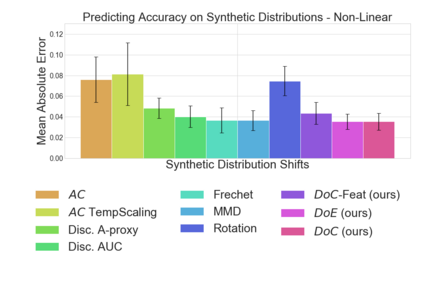
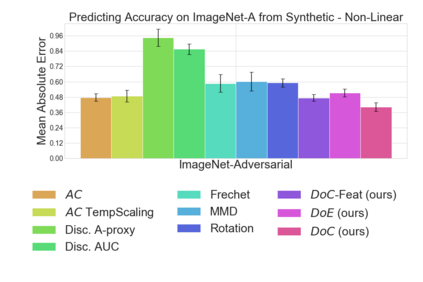
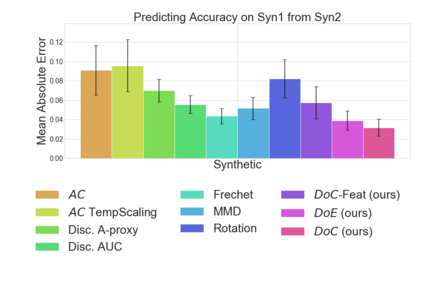
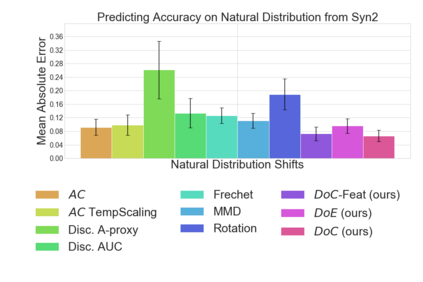
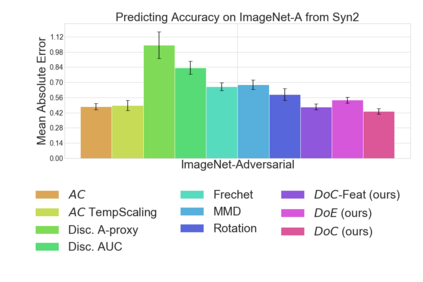
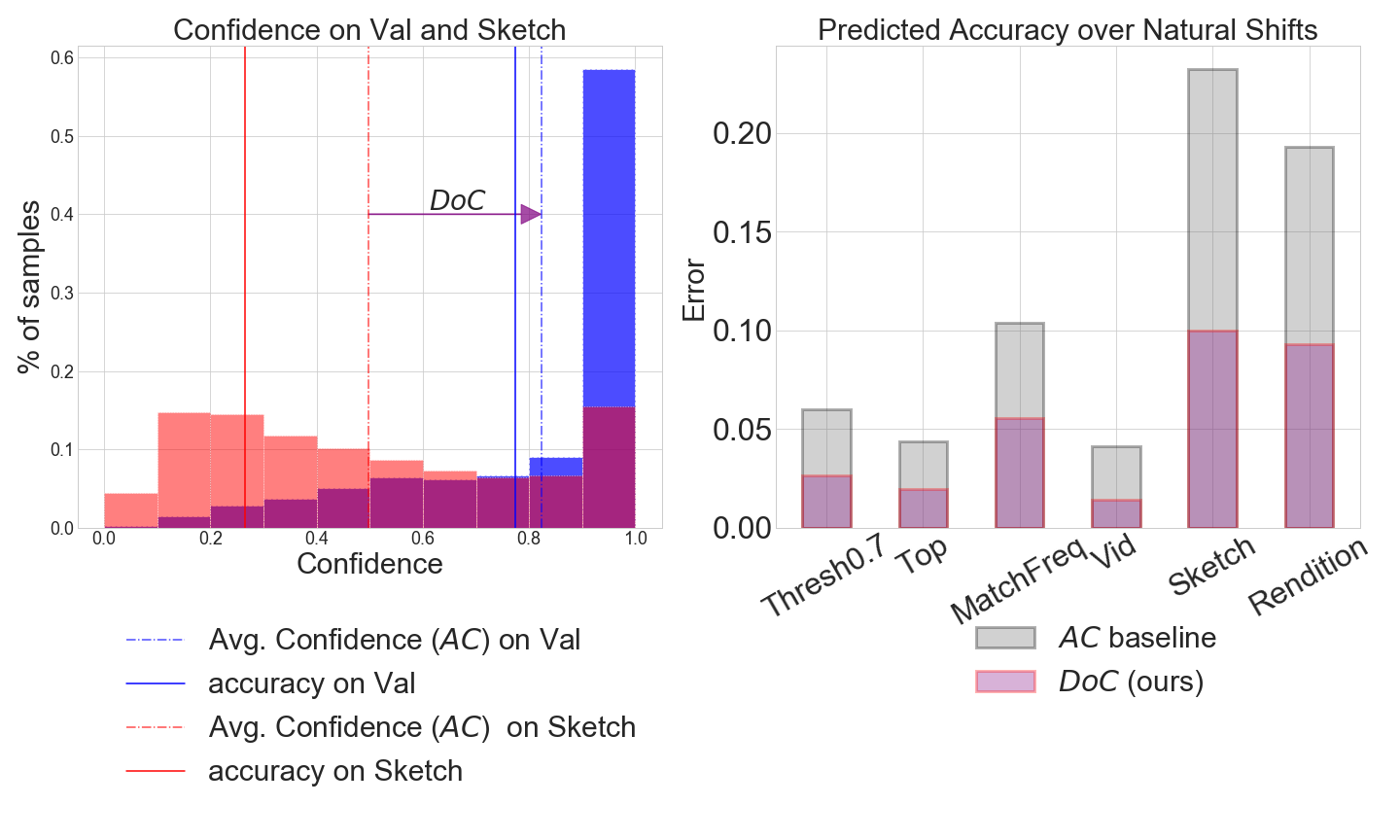
Recent work has shown that the performance of machine learning models can vary substantially when models are evaluated on data drawn from a distribution that is close to but different from the training distribution. As a result, predicting model performance on unseen distributions is an important challenge. Our work connects techniques from domain adaptation and predictive uncertainty literature, and allows us to predict model accuracy on challenging unseen distributions without access to labeled data. In the context of distribution shift, distributional distances are often used to adapt models and improve their performance on new domains, however accuracy estimation, or other forms of predictive uncertainty, are often neglected in these investigations. Through investigating a wide range of established distributional distances, such as Frechet distance or Maximum Mean Discrepancy, we determine that they fail to induce reliable estimates of performance under distribution shift. On the other hand, we find that the difference of confidences (DoC) of a classifier's predictions successfully estimates the classifier's performance change over a variety of shifts. We specifically investigate the distinction between synthetic and natural distribution shifts and observe that despite its simplicity DoC consistently outperforms other quantifications of distributional difference. $DoC$ reduces predictive error by almost half ($46\%$) on several realistic and challenging distribution shifts, e.g., on the ImageNet-Vid-Robust and ImageNet-Rendition datasets.
翻译:最近的工作表明,当根据分布接近但不同于培训分布的数据对模型的分布数据进行评估时,机器学习模型的性能可以大不相同。因此,预测无形分布的模型性能是一项重大挑战。我们的工作将领域适应和预测不确定性文献的技术联系起来,使我们能够预测挑战性无形分布的模型性能,而没有获得标签数据。在分布转移方面,分配距离常常被用来调整模型,改进新领域的性能,而精确估计或其他形式的预测性不确定性往往在这些调查中被忽视。通过调查各种既定的分布距离,例如Frechet距离或最大平均值偏差,我们确定这些模型未能产生对分布变化中的性能的可靠估计。另一方面,我们发现一个分类器预测的可信度差异(DoC)成功地估计了分类器在各种变化中的性能变化。我们特别调查合成和自然分布变化之间的区别,并观察到尽管DoC的简单程度持续超过对分布差异的其他量化,例如Frechet 距离或最大平均值偏差,我们确定它们未能产生可靠的对分布变化的可靠估计。另一方面,我们发现,一个分类器的预测值之间的信任差异通过现实化数据流差($) 和图像分布上几乎一半的预测错误。