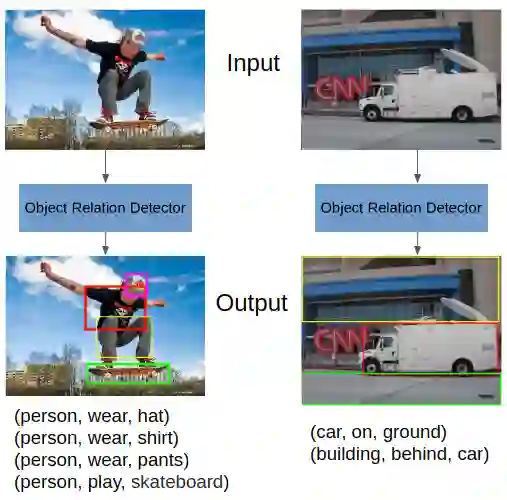
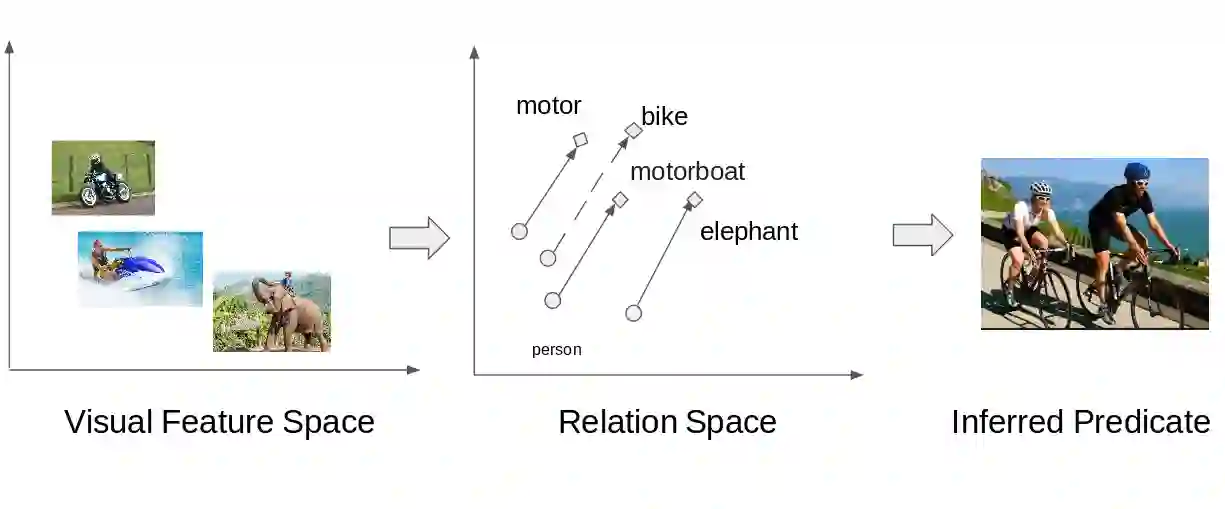
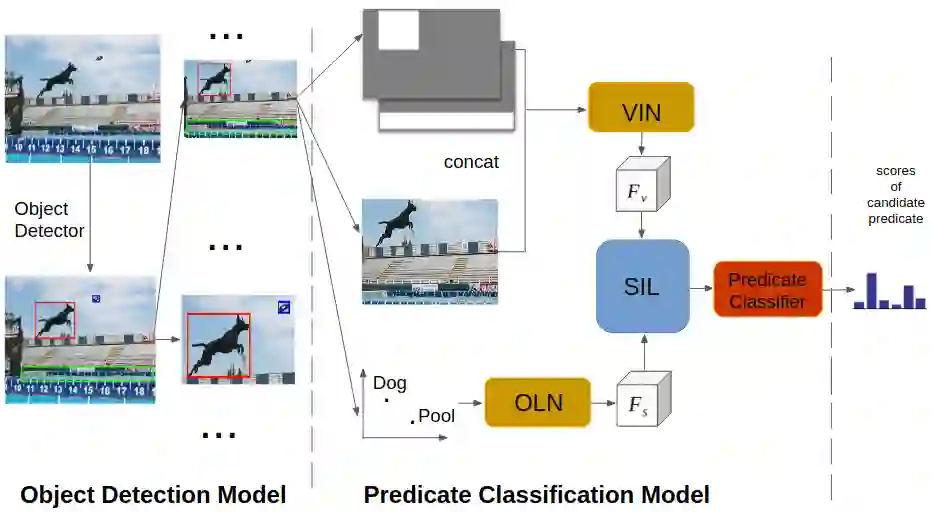
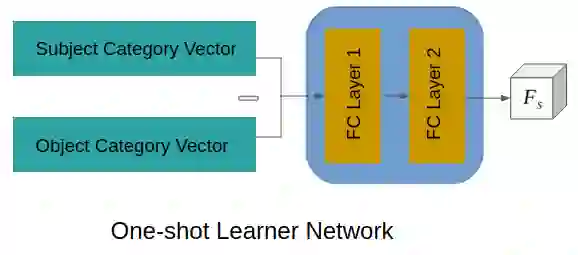
Detecting the relations among objects, such as "cat on sofa" and "person ride horse", is a crucial task in image understanding, and beneficial to bridging the semantic gap between images and natural language. Despite the remarkable progress of deep learning in detection and recognition of individual objects, it is still a challenging task to localize and recognize the relations between objects due to the complex combinatorial nature of various kinds of object relations. Inspired by the recent advances in one-shot learning, we propose a simple yet effective Semantics Induced Learner (SIL) model for solving this challenging task. Learning in one-shot manner can enable a detection model to adapt to a huge number of object relations with diverse appearance effectively and robustly. In addition, the SIL combines bottom-up and top-down attention mech- anisms, therefore enabling attention at the level of vision and semantics favorably. Within our proposed model, the bottom-up mechanism, which is based on Faster R-CNN, proposes objects regions, and the top-down mechanism selects and integrates visual features according to semantic information. Experiments demonstrate the effectiveness of our framework over other state-of-the-art methods on two large-scale data sets for object relation detection.
翻译:尽管在发现和识别个别物体方面有显著的深刻学习,但由于各种物体关系的复杂组合性质,定位和认识物体之间的关系仍然是一项艰巨的任务。我们根据最近一手学习的进展,提出了解决这项富有挑战性的任务的简单而有效的语义教学模式(SIL),建议采用自下而上的机制,并采用自上而下的机制,根据两手掌握的信息,选择和整合视觉特征。实验显示我们框架在州一级其他数据系统中的有效性。