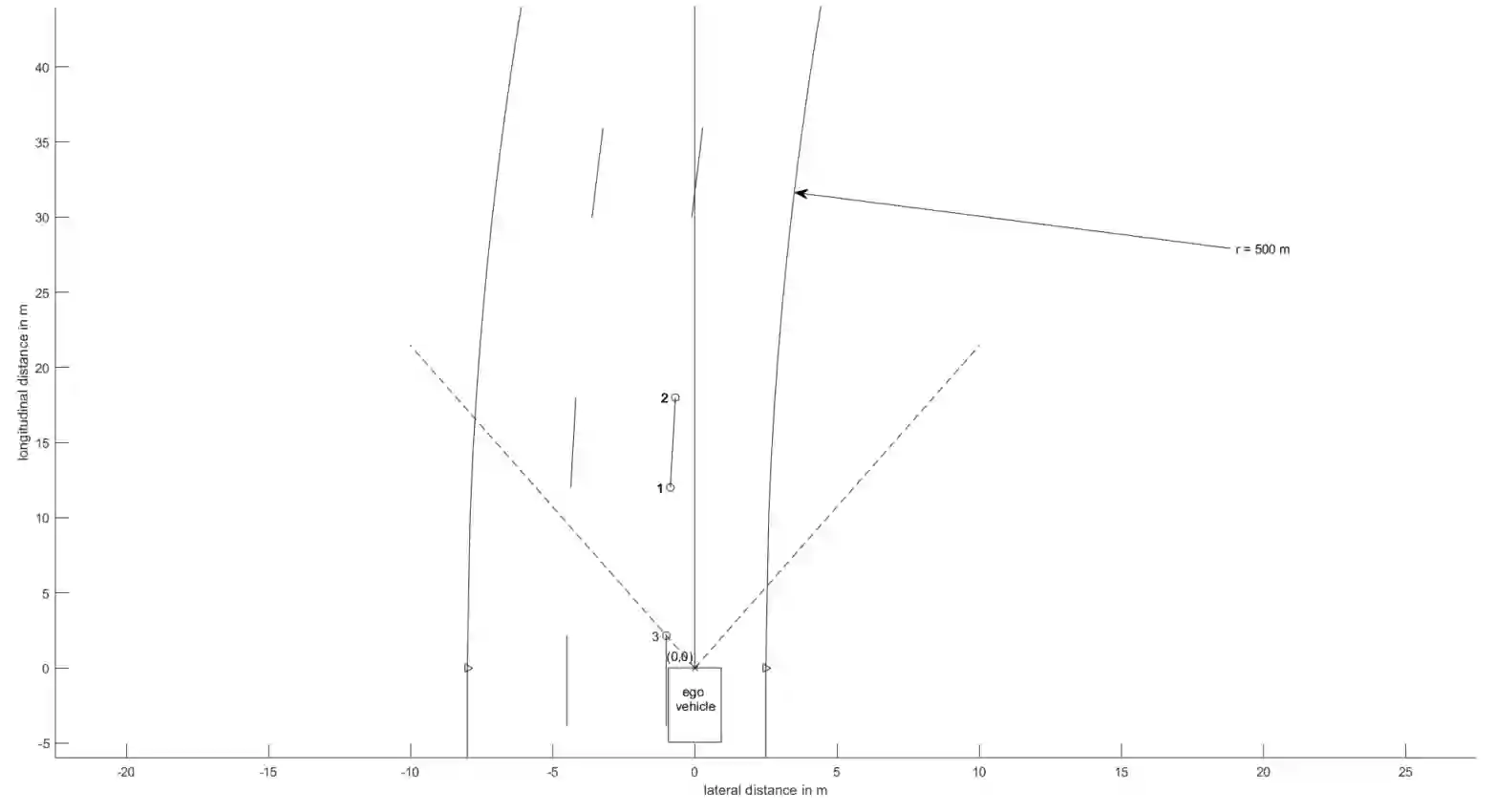
Virtual development and prototyping has already become an integral part in the field of automated driving systems (ADS). There are plenty of software tools that are used for the virtual development of ADS. One such tool is CarMaker from IPG Automotive, which is widely used in the scientific community and in the automotive industry. It offers a broad spectrum of implementation and modelling possibilities of the vehicle, driver behavior, control, sensors, and environmental models. Focusing on the virtual development of highly automated driving functions on the vehicle guidance level, it is essential to perceive the environment in a realistic manner. For the longitudinal and lateral path guidance line detection sensors are necessary for the determination of the relevant perceiving vehicle and for the planning of trajectories. For this purpose, a lane sensor model was developed in order to efficiently detect lanes in the simulation environment of CarMaker. The so-called advanced lane detection model (ALDM) is optimized regarding the calculation time and is for the lateral and longitudinal vehicle guidance in CarMaker.
翻译:虚拟开发和原型设计已成为自动驾驶系统(ADS)领域的一个组成部分。许多软件工具都用于自动驾驶系统(ADS)的虚拟发展。其中一个工具是来自IPG汽车的CarMaker,它在科学界和汽车工业中广泛使用。它提供了车辆、驾驶员行为、控制、传感器和环境模型的广泛实施和建模可能性。侧重于在车辆导航水平上虚拟开发高度自动化的驾驶功能,必须现实地看待环境。对于确定相关感知器和轨迹规划而言,需要纵向和横向路径指导线探测传感器。为此目的,开发了一条航道传感器模型,以便在CarMaker模拟环境中高效地探测航道。所谓的高级航道探测模型(ALDM)在计算时间方面得到了优化,用于CarMaker的横向和纵向车辆指导。