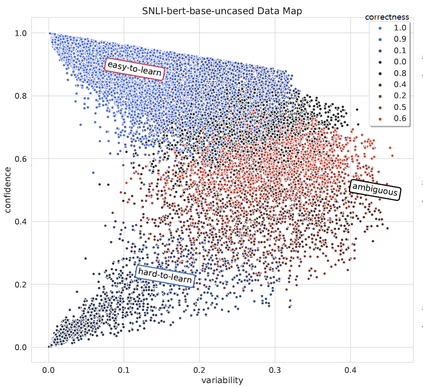
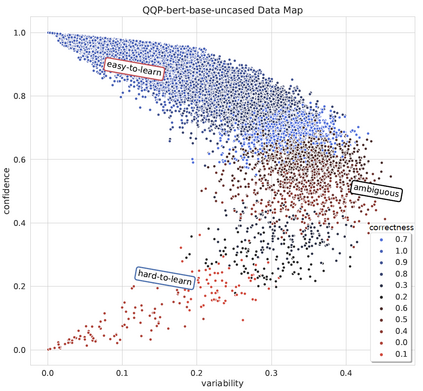
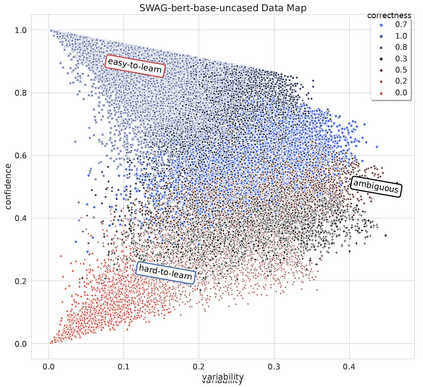
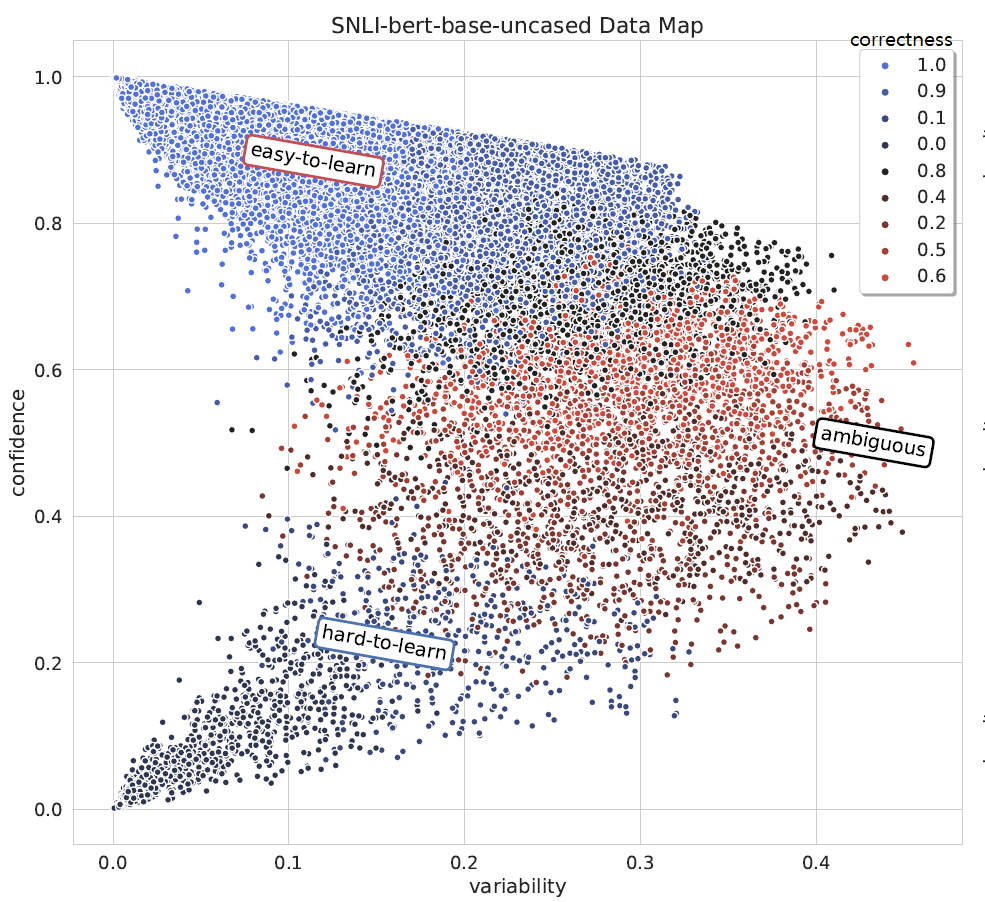
MixUp is a data augmentation strategy where additional samples are generated during training by combining random pairs of training samples and their labels. However, selecting random pairs is not potentially an optimal choice. In this work, we propose TDMixUp, a novel MixUp strategy that leverages Training Dynamics and allows more informative samples to be combined for generating new data samples. Our proposed TDMixUp first measures confidence, variability, (Swayamdipta et al., 2020), and Area Under the Margin (AUM) (Pleiss et al., 2020) to identify the characteristics of training samples (e.g., as easy-to-learn or ambiguous samples), and then interpolates these characterized samples. We empirically validate that our method not only achieves competitive performance using a smaller subset of the training data compared with strong baselines, but also yields lower expected calibration error on the pre-trained language model, BERT, on both in-domain and out-of-domain settings in a wide range of NLP tasks. We publicly release our code.
翻译:混合是一种数据增强战略,在培训期间通过将随机培训样本及其标签组合在一起产生更多的样本。然而,随机选择对配对并不是一个潜在的最佳选择。在这项工作中,我们提出TDMixUp,这是一个创新的混合战略,它利用培训动态,允许将信息性更强的样本组合起来以产生新的数据样本。我们提议的TDMixUp首先测量信心、变异性(Swayamdipta等人,2020年)和Margin地区(AUM)(Pleiss等人,2020年),以确定培训样本的特征(例如,容易阅读或模糊的样本),然后将这些样本进行内插。我们通过经验验证,我们的方法不仅利用培训数据中的一小部分与强力基线相比具有竞争力,而且还在广泛的非常规任务中,在事先培训的语言模型BERT上产生较低的预期校准错误。我们公开发布了我们的代码。