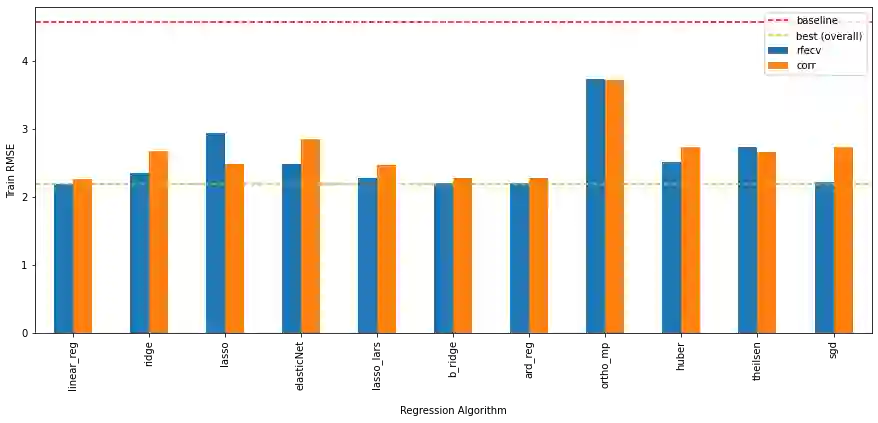
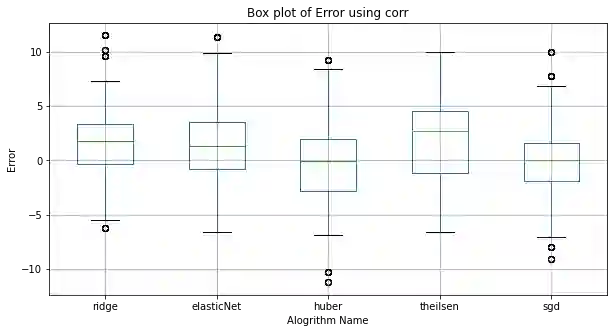
The average life expectancy is increasing globally due to advancements in medical technology, preventive health care, and a growing emphasis on gerontological health. Therefore, developing technologies that detect and track aging-associated disease in cognitive function among older adult populations is imperative. In particular, research related to automatic detection and evaluation of Alzheimer's disease (AD) is critical given the disease's prevalence and the cost of current methods. As AD impacts the acoustics of speech and vocabulary, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of ten linear regression models for predicting Mini-Mental Status Exam scores on the ADReSS challenge dataset. We extracted 13000+ handcrafted and learned features that capture linguistic and acoustic phenomena. Using a subset of 54 top features selected by two methods: (1) recursive elimination and (2) correlation scores, we outperform a state-of-the-art baseline for the same task. Upon scoring and evaluating the statistical significance of each of the selected subset of features for each model, we find that, for the given task, handcrafted linguistic features are more significant than acoustic and learned features.
翻译:由于医疗技术、预防性保健的进步和对老年保健的日益重视,全球平均预期寿命正在增加。因此,必须开发技术,检测和跟踪老年人口认知功能中的与老龄化有关的疾病。特别是,鉴于该疾病发病率和当前方法的成本,有关阿尔茨海默氏病(AD)自动检测和评估的研究至关重要。由于AD影响语言和词汇的声学,自然语言处理和机器学习为可靠地探测AD提供了有希望的技术。我们比较和比较了用于预测ADRESS挑战数据集中微型和中型状态Exam分数的十种线性回归模型的性能。我们提取了13 000+手工艺和学习的特征,这些特征反映了语言和声学现象。使用两种方法选择的54个顶点:(1) 循环消除和(2) 相关分数,我们比同一任务中最先进的基线。在评分和评价每一选定特征的统计重要性之后,我们发现,手写语言特征对于特定任务比声学和学习特征更重要。