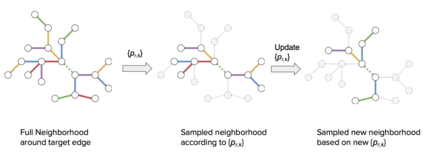
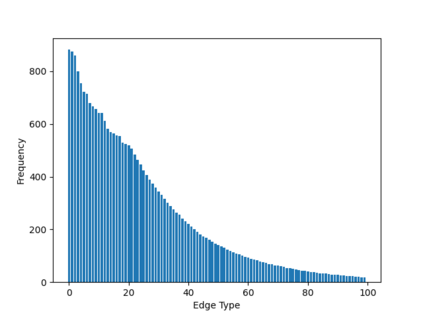
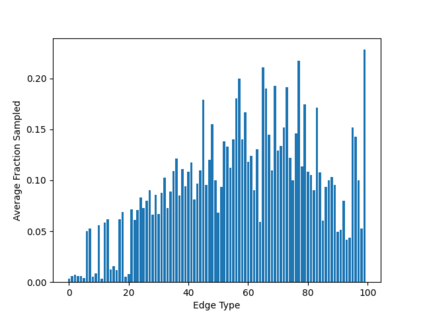
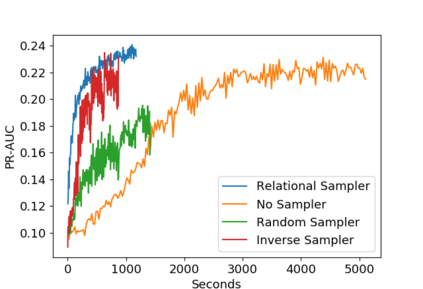
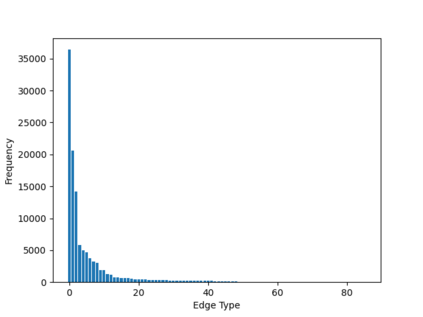
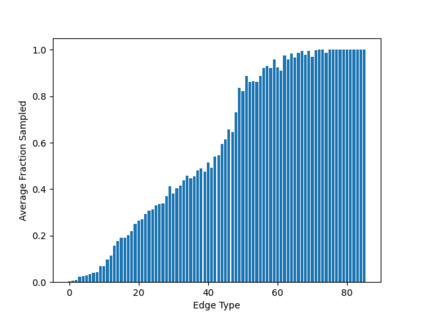
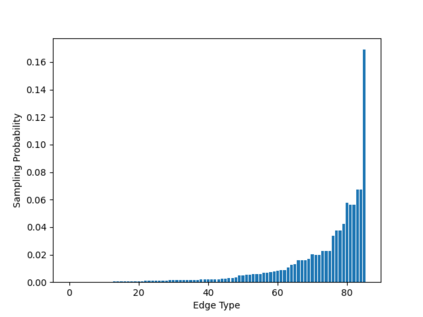
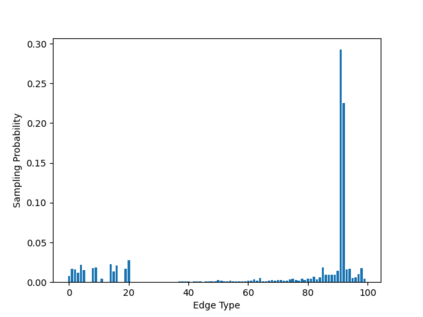
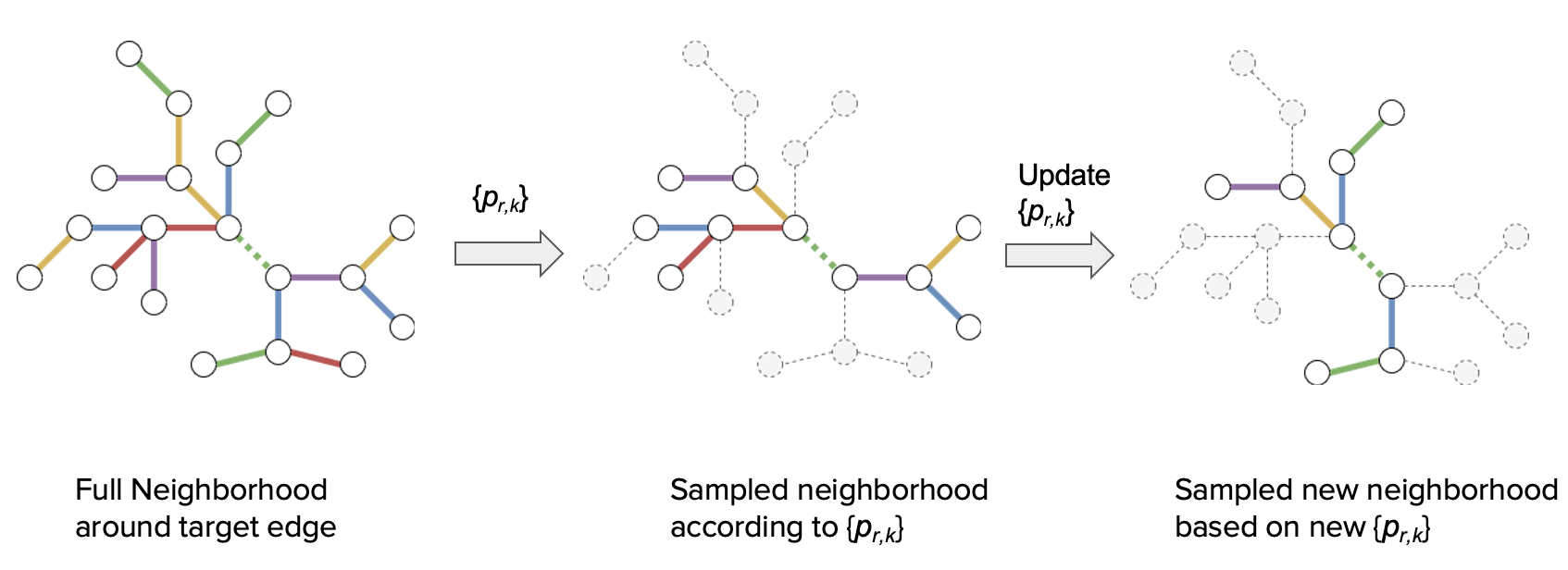
Sampling is an established technique to scale graph neural networks to large graphs. Current approaches however assume the graphs to be homogeneous in terms of relations and ignore relation types, critically important in biomedical graphs. Multi-relational graphs contain various types of relations that usually come with variable frequency and have different importance for the problem at hand. We propose an approach to modeling the importance of relation types for neighborhood sampling in graph neural networks and show that we can learn the right balance: relation-type probabilities that reflect both frequency and importance. Our experiments on drug-drug interaction prediction show that state-of-the-art graph neural networks profit from relation-dependent sampling in terms of both accuracy and efficiency.
翻译:取样是一种将图形神经网络缩放成大图的既定技术。但是,目前的方法假定图表在关系方面是同质的,忽略了关系类型,在生物医学图表中至关重要。多关系图表包含各种类型的关系,通常具有不同频率,对当前问题具有不同的重要性。我们建议一种方法,在图形神经网络中建模邻里类型对社区取样的重要性,并表明我们可以学到正确的平衡:反映频率和重要性的关系类型概率。我们在药物-药物相互作用预测方面的实验表明,最先进的图形神经网络从基于关系取样的准确性和效率方面获益。